GPT-OSS-120B Deployment Guide on HPC-AI.COM
We are excited to announce the open-source release of GPT-OSS-120B, a large language model built for production-grade applications, general-purpose tasks, and advanced reasoning. At HPC-AI.COM, you can easily deploy this model with unmatched efficiency and convenience powered by our high-performance infrastructure.
1. Environment Setup
1.1 Pre-configured Development Environment
We provide ready-to-use high-performance development environments. Simply select a pre-built image (e.g., CUDA 12.8) to launch a full-featured GPU cloud instance.
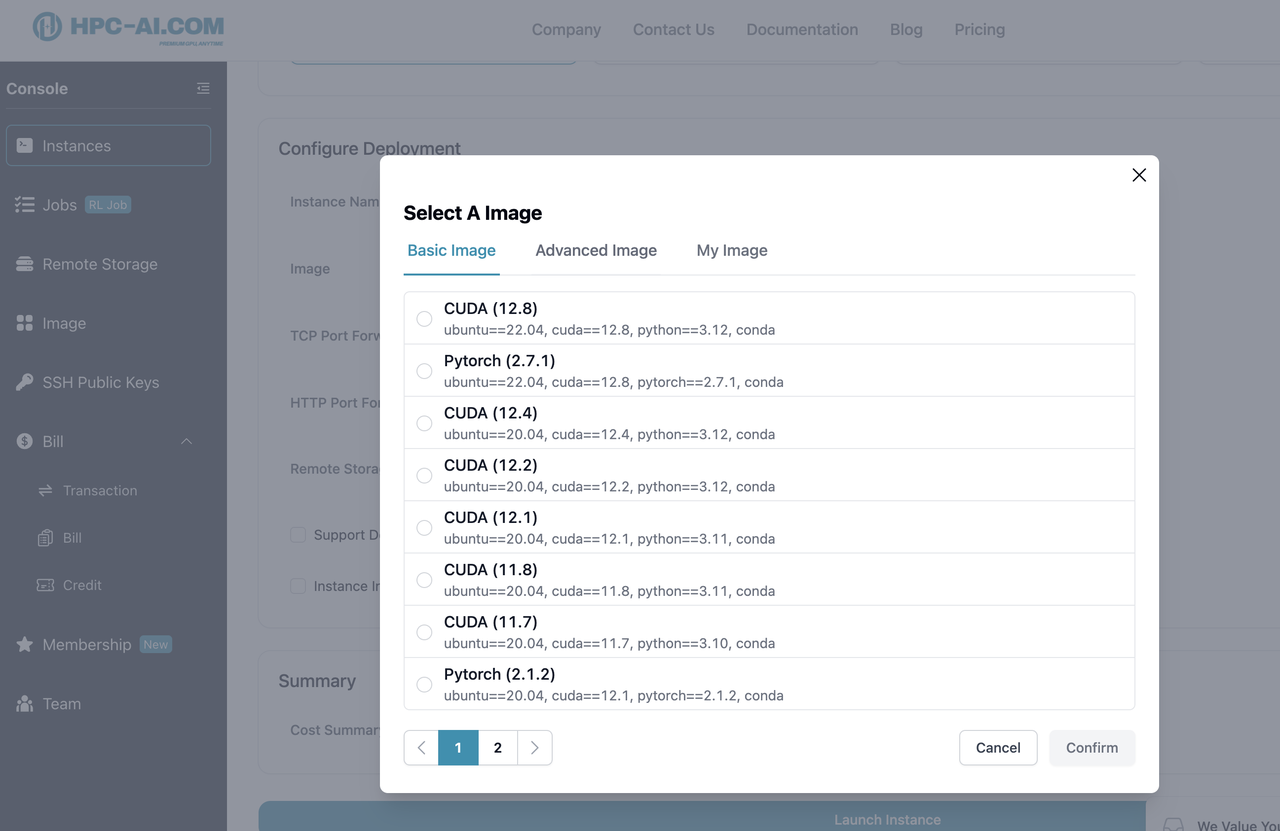
1.2 Install Your Preferred Inference Framework
After launching your instance, install the inference framework that best suits your needs.
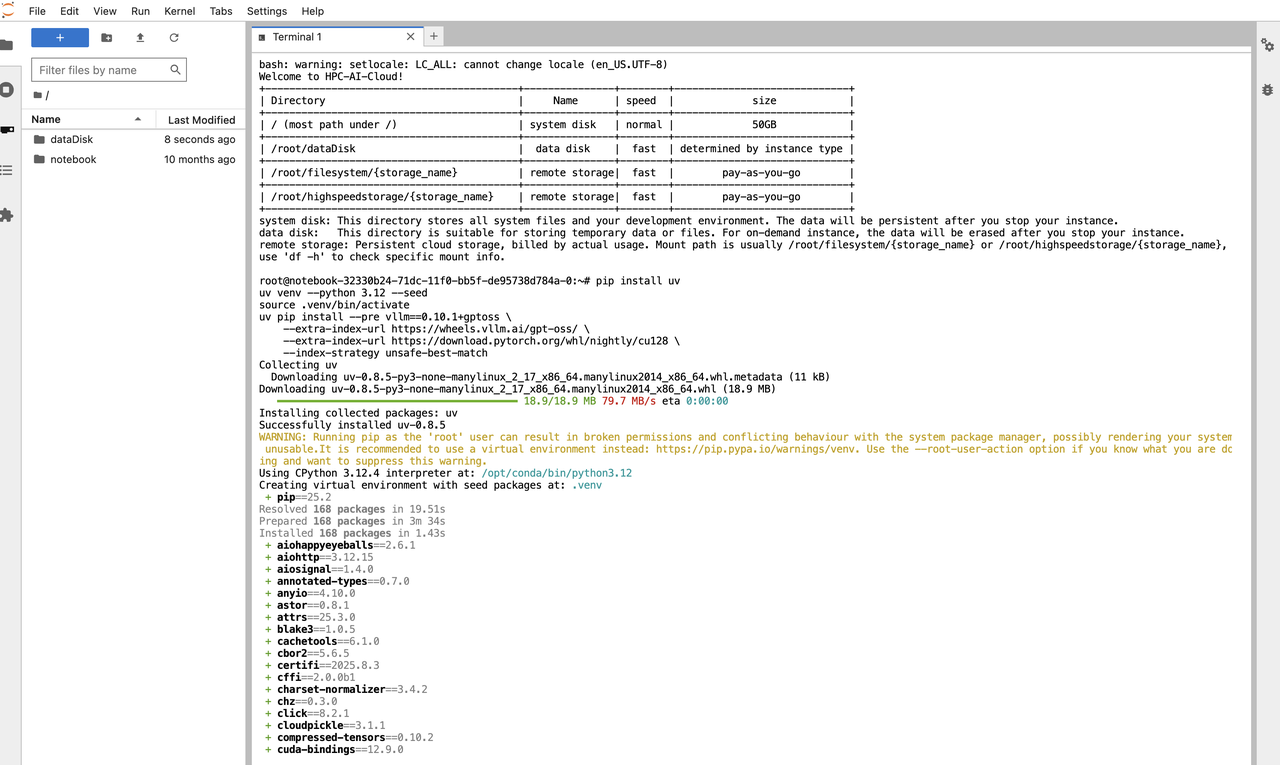
For example, to set up a basic vLLM environment:
pip install uv
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
2. Model Privatization
We provide cluster-level caching to load models at exceptional speed. For instance, the entire 183GB GPT-OSS-120B model can be downloaded in under 5 minutes, with speeds up to 1.1 GB/s.
We also configure data disks and high-speed shared storage so you can easily access the model in a fully isolated environment.
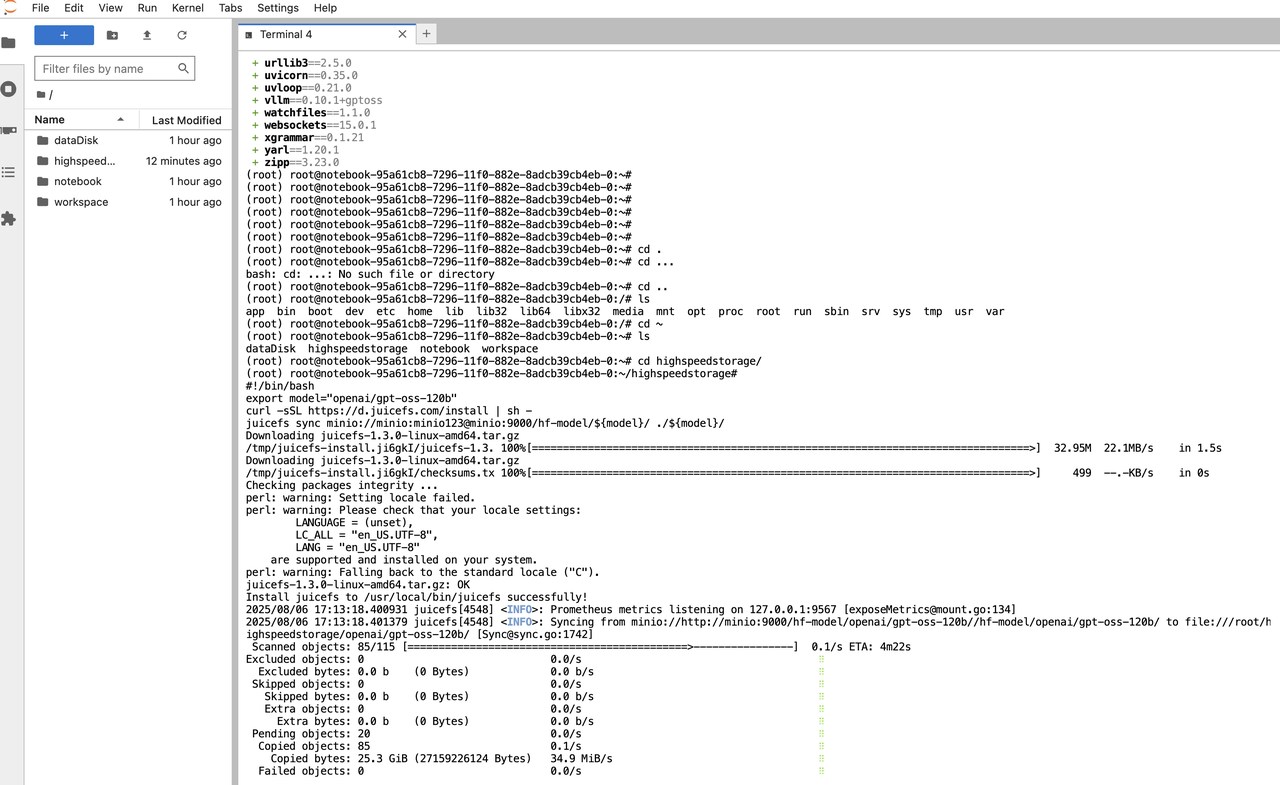
Example: Privatized Model Download
cd ${YourModelPath}
#!/bin/bash
export model="openai/gpt-oss-120b"
curl -sSL https://d.juicefs.com/install | sh -
juicefs sync minio://minio:minio123@minio:9000/hf-model/${model}/ ./${model}/
3. Public Inference Service
We support public HTTP forwarding so you can expose your inference endpoint to the internet.
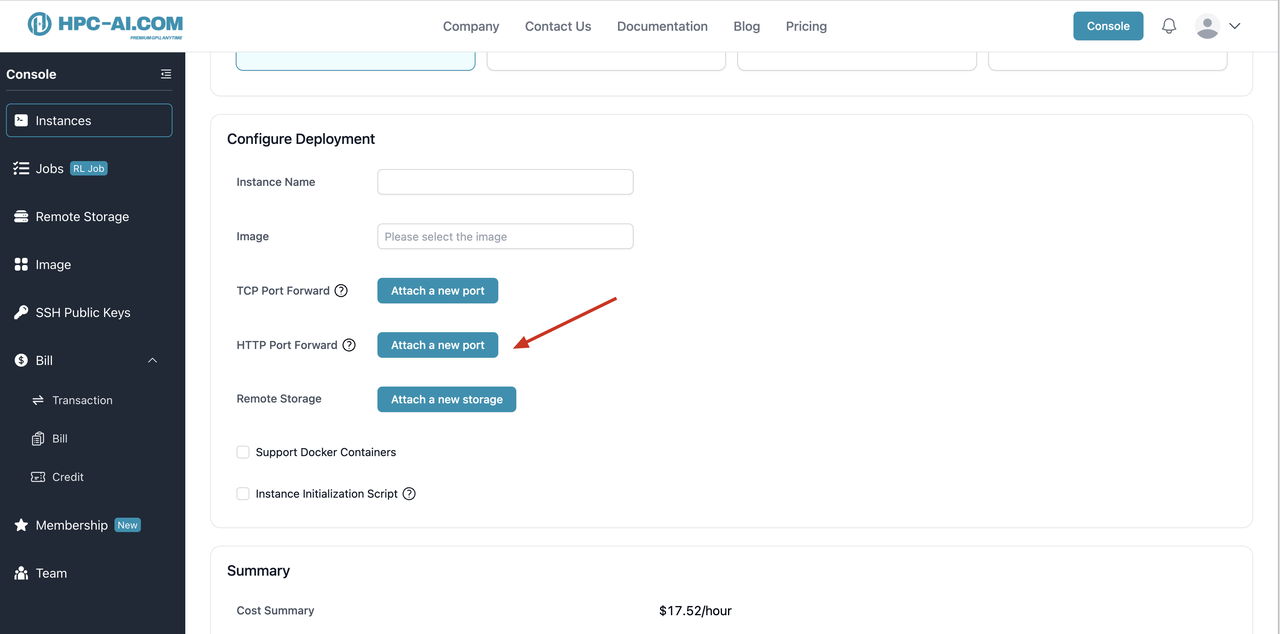
Start a vLLM server on 8 high-performance GPUs using:
vllm serve ${modelPath} --tensor-parallel-size 8
📌 Note: In vLLM, the
modelPathmust match the value passed as the model name.
Sample Forwarding Address:
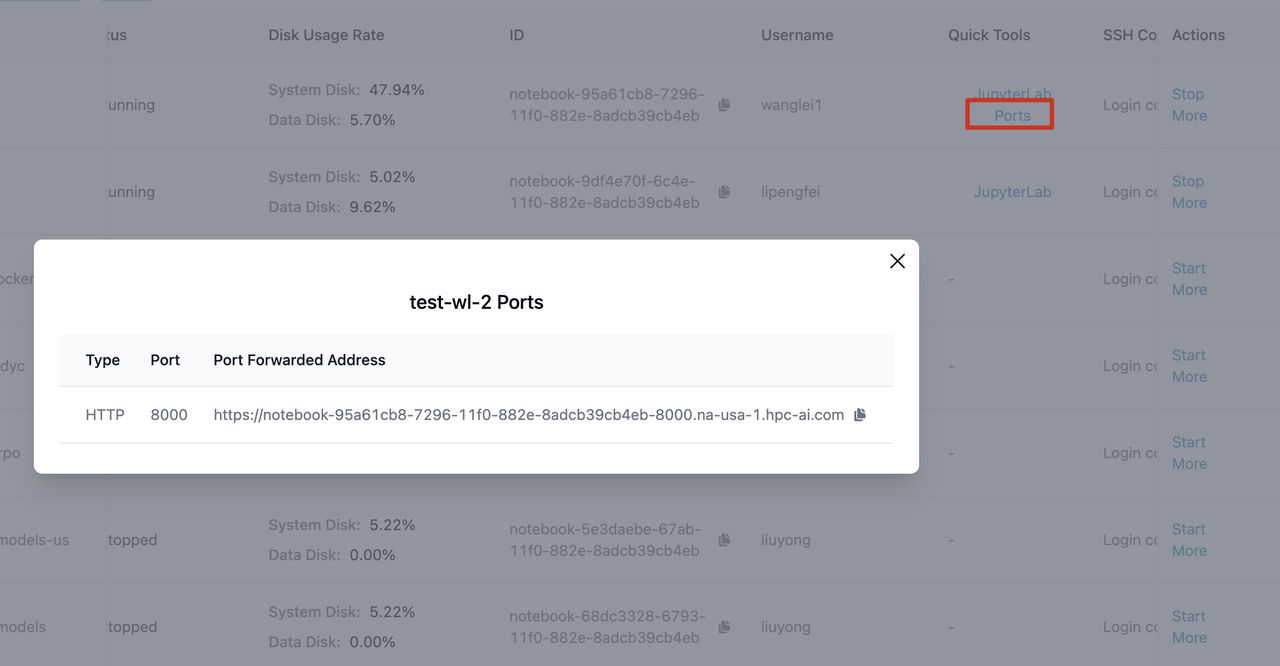
https://notebook-95a61cb8-7296-11f0-882e-8adcb39cb4eb-8000.na-usa-1.hpc-ai.com
Test with curl
curl -s https://notebook-95a61cb8-7296-11f0-882e-8adcb39cb4eb-8000.na-usa-1.hpc-ai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "${modelPath}",
"messages": [{"role": "user", "content": "Hello, please introduce yourself"}],
"max_tokens": 100
}'
HPC-AI.COM Performance Demo
✅ Complex Task Inference:
Single machine throughput: 200 tokens/s on tasks like BIG-Bench Hard – Web of Lies.
Sample Request:
curl -X POST "https://notebook-95a61cb8-7296-11f0-882e-8adcb39cb4eb-8000.na-usa-1.hpc-ai.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer EMPTY" \
-d '{
"model": "${ModelPath}",
"messages": [{
"role": "user",
"content": "Solve this logic puzzle: There are 4 people - Alice, Bob, Charlie, Diana..."
}],
"max_tokens": 8192
}'
Performance Logs
Avg generation throughput: 249.9 tokens/s
Prefix cache hit rate: 39.1%
✅ Tool Use + Streaming Inference:
Tool-assisted generation at 160 tokens/s
Request:
curl -X POST "https://notebook-95a61cb8-7296-11f0-882e-8adcb39cb4eb-8000.na-usa-1.hpc-ai.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer EMPTY" \
-d '{
"model": "/root/dataDisk/openai/gpt-oss-120b/",
"messages": [{
"role": "user",
"content": "I need to analyze NVIDIA stock. Please search for recent earnings news and get the current stock price."
}],
"tools": [
{
"type": "function",
"function": {
"name": "web_search",
"description": "Search for information",
"parameters": {
"type": "object",
"properties": {
"query": { "type": "string" }
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "get_stock_price",
"description": "Get stock price",
"parameters": {
"type": "object",
"properties": {
"symbol": { "type": "string" }
},
"required": ["symbol"]
}
}
}
],
"max_tokens": 4096
}'
Agentic Inference with OpenAI Agent SDK
You can use the OpenAI Agent SDK to build tool-using agents with GPT-OSS:
Example Code
import asyncio
from openai import AsyncOpenAI
from agents import Agent, Runner, function_tool, OpenAIResponsesModel, set_tracing_disabled
set_tracing_disabled(True)
@function_tool
def get_weather(city: str):
print(f"[debug] getting weather for {city}")
return f"The weather in {city} is sunny."
async def main():
agent = Agent(
name="Assistant",
instructions="You only respond in haikus.",
model=OpenAIResponsesModel(
model="/root/dataDisk/openai/gpt-oss-120b/",
openai_client=AsyncOpenAI(
base_url="http://localhost:8000/v1",
api_key="EMPTY",
),
),
tools=[get_weather],
)
result = await Runner.run(agent, "What's the weather in Tokyo?")
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
Output Example
[debug] getting weather for Tokyo
Tokyo sun glows bright
Cherry blossoms smile anew
Gentle warmth embraces