Deployment Tongyi-DeepResearch-30B-A3B Model
Tongyi-DeepResearch-30B-A3B is a large-scale model launched by Alibaba, specializing in handling complex tasks that require in-depth analysis, information retrieval, and multi-step reasoning. Built on the HPC-AI.COM infrastructure, you can easily deploy this model and quickly put it into practical use.
1. Development Environment Pre-Configuration
First, you need a high-performance cloud instance to support the model's operation. You can choose a pre-built image, such as one that includes CUDA 12.8.
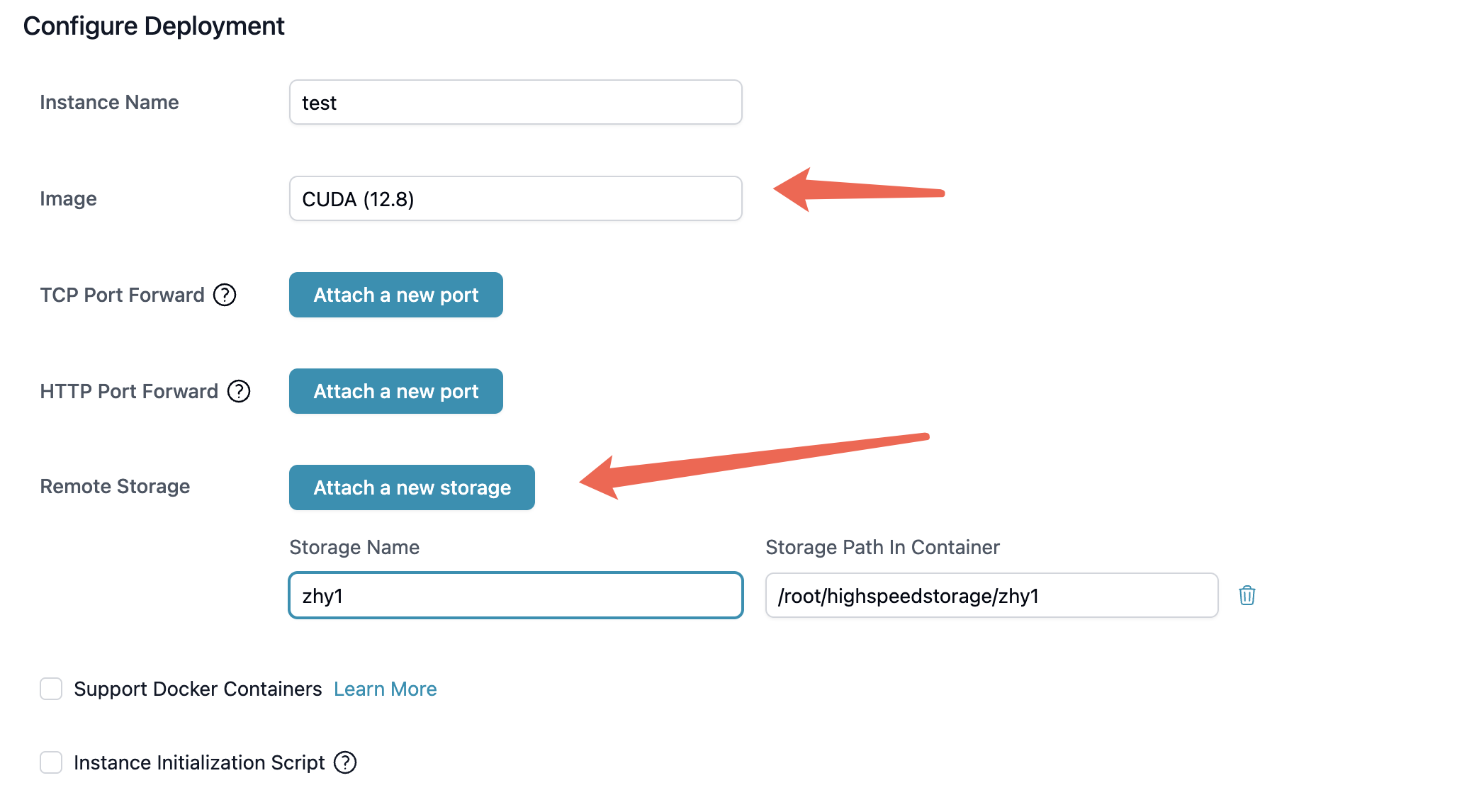
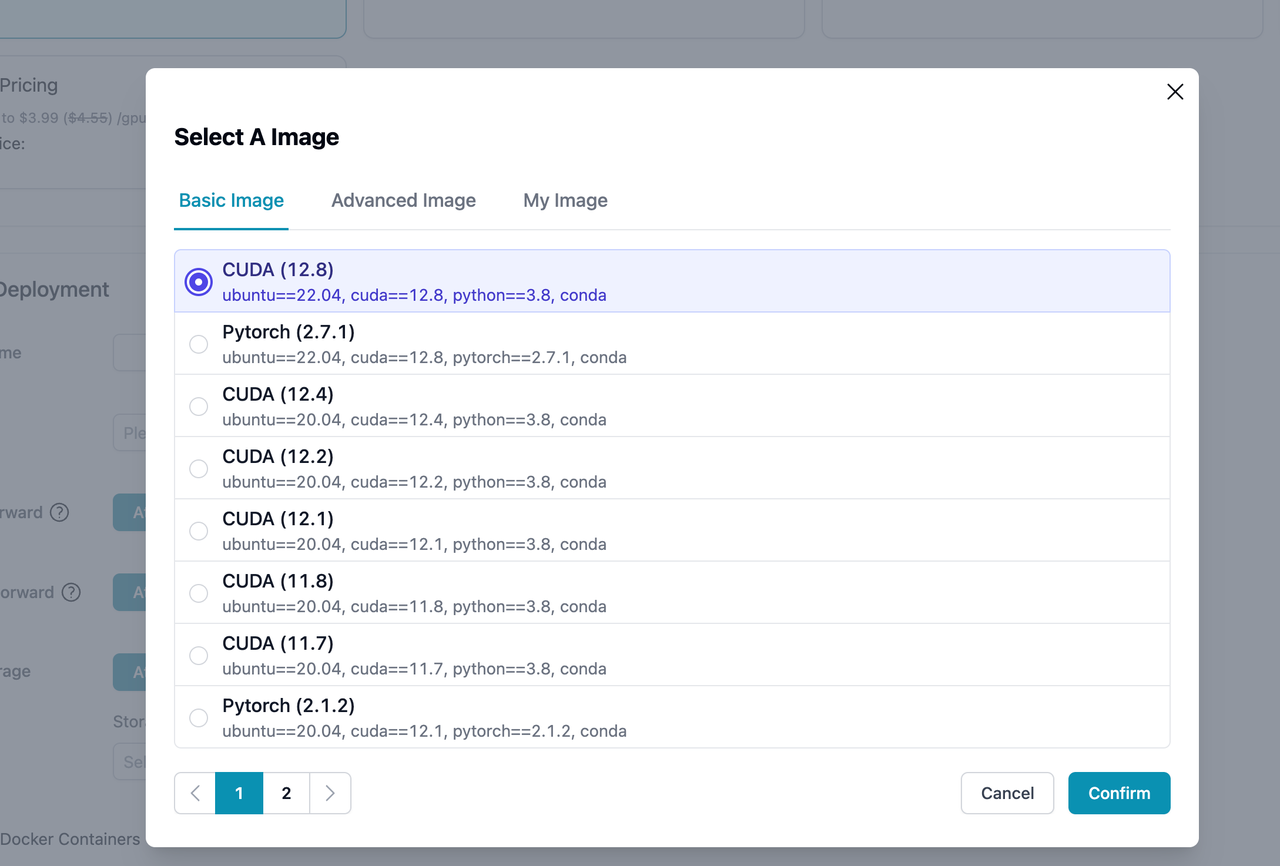
2. Install the Inference Framework
After launching your cloud instance, the next step is to install the inference framework that suits your needs. For example, if you plan to use vLLM as your inference engine, you can follow these steps:
pip install uv
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install vllm \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
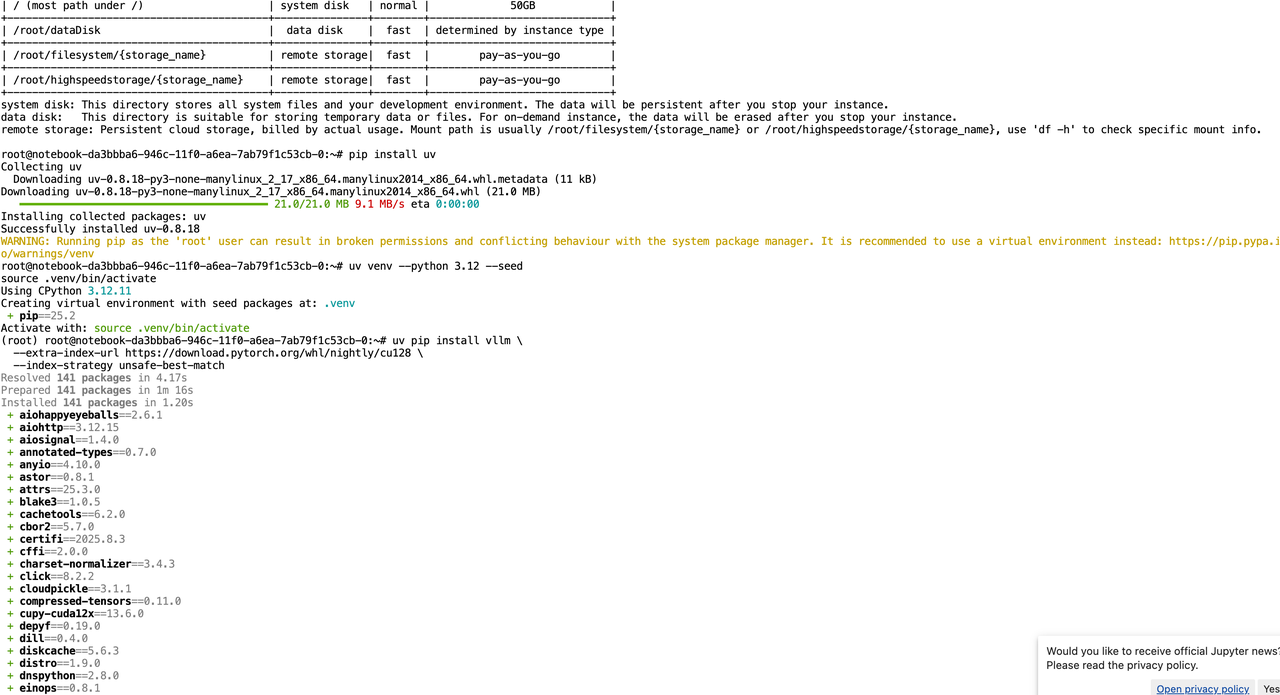
3. Model Privatization
We utilize local storage as a cache to support on-demand loading of model files. By combining data disks with high-speed shared storage, this enables fast deployment and stable access of large models in isolated environments.
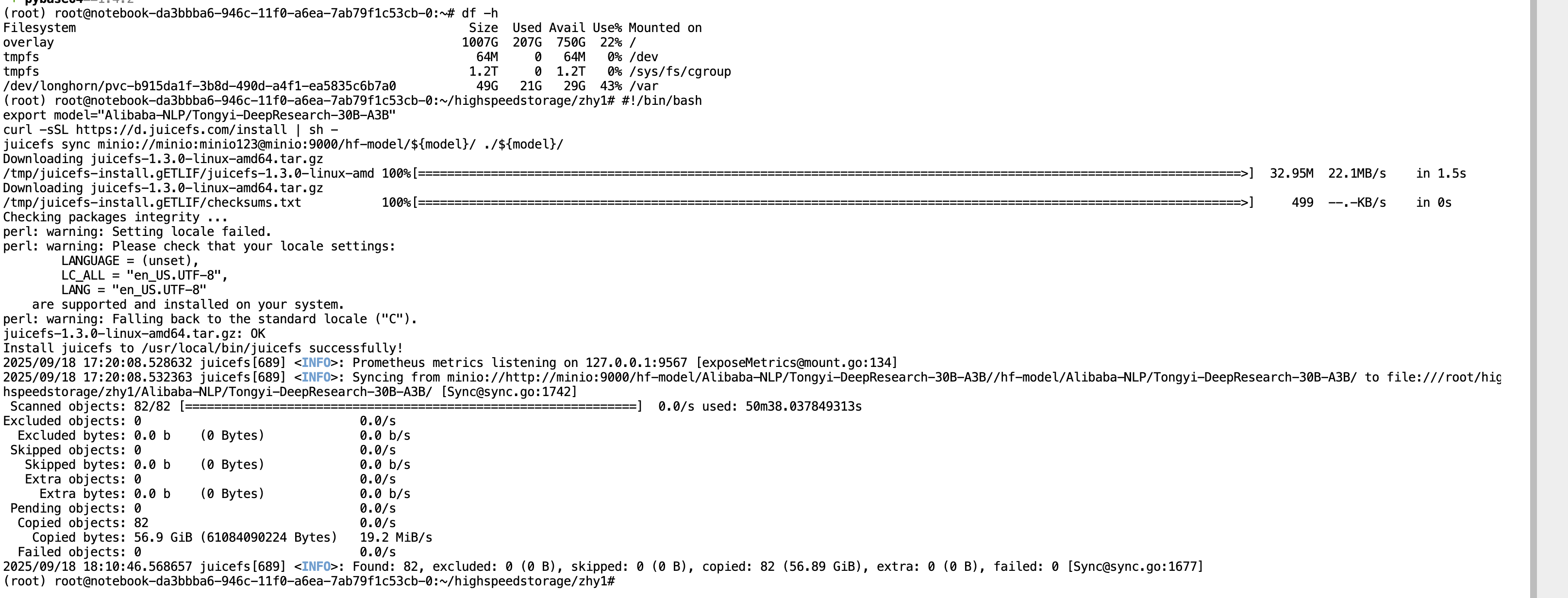
You can download the model to high-speed shared storage to ensure efficient read and write operations.
cd highspeedstorage/zhy1/
#!/bin/bash
export model="Alibaba-NLP/Tongyi-DeepResearch-30B-A3B"
curl -sSL https://d.juicefs.com/install | sh -
juicefs sync minio://minio:minio123@minio:9000/hf-model/${model}/ ./${model}/
4. Public Inference Service
Our platform supports public HTTP forwarding, allowing inference endpoints to be exposed to the internet for convenient remote access.
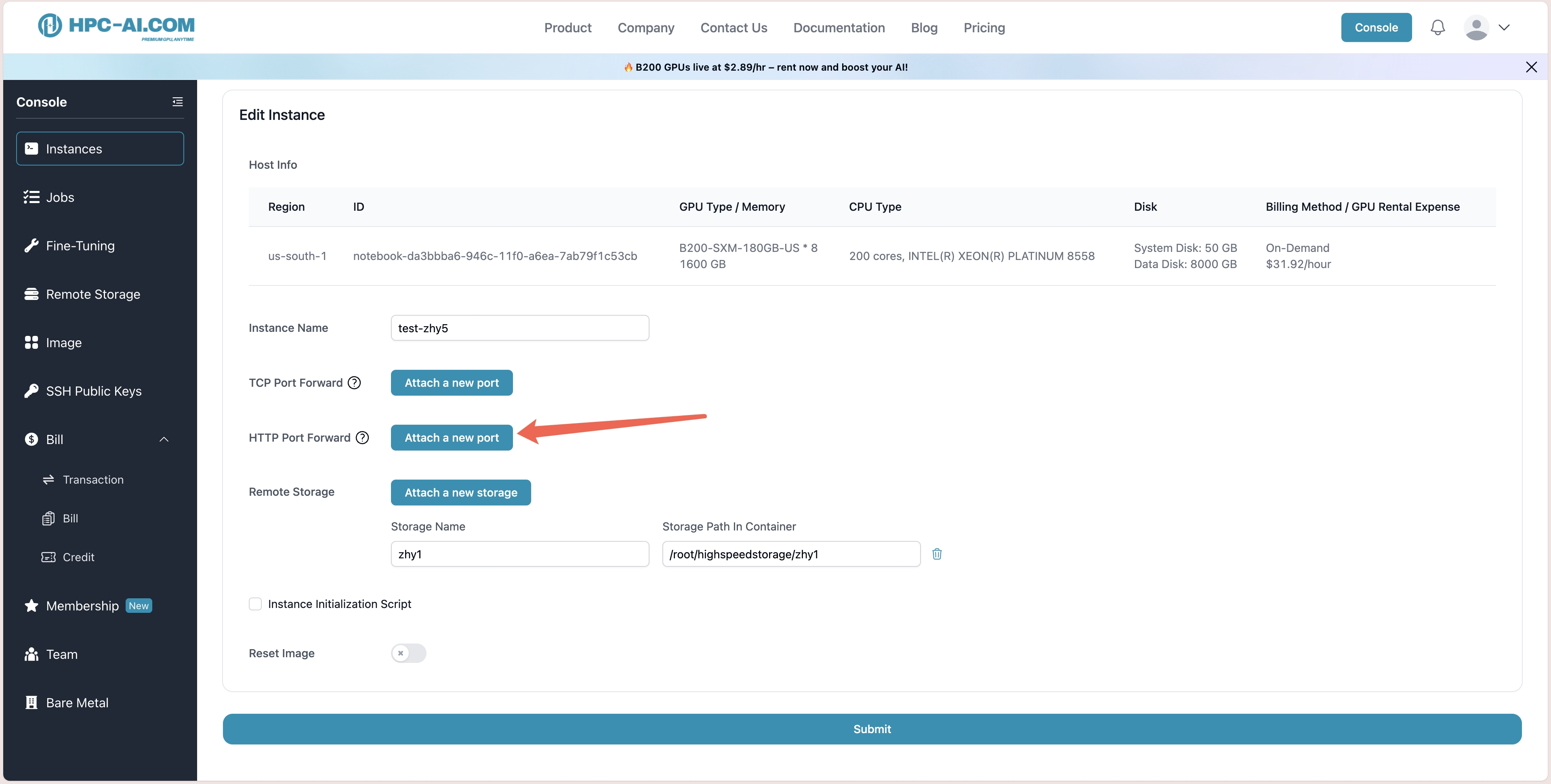
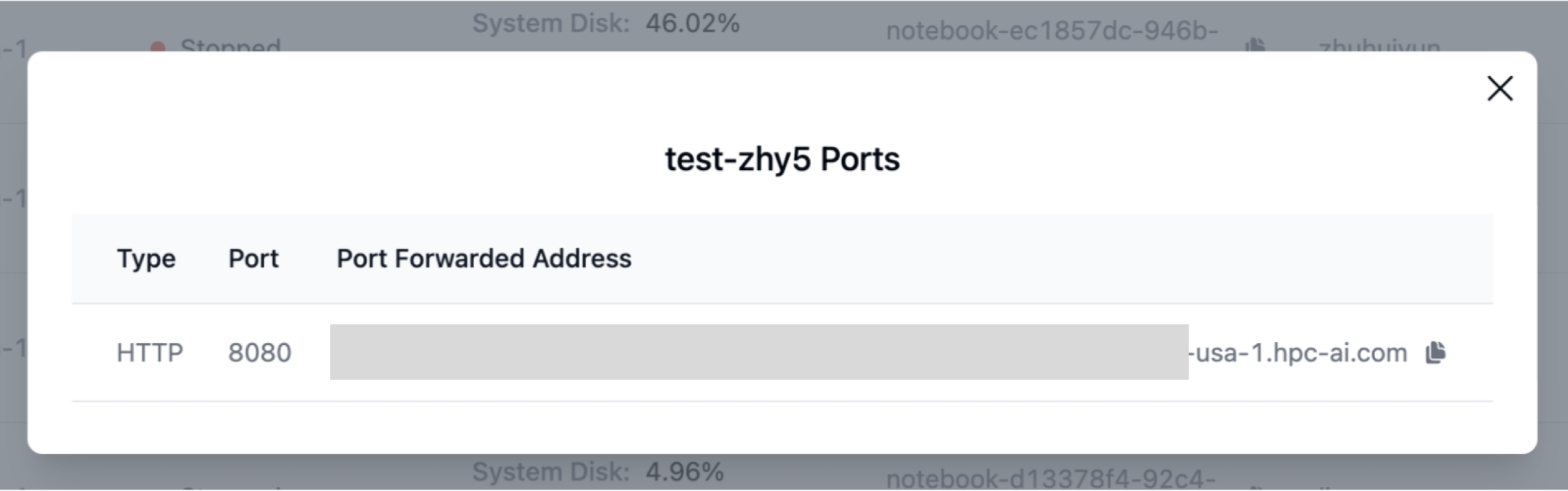
python -m vllm.entrypoints.openai.api_server \
--model /root/highspeedstorage/zhy1/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B \
--tensor-parallel-size 8 \
--port 8080
Validate Service Accessibility
curl https://notebook-38c181af-9501-11f0-a6ea-7ab79f1c53cb-8080.na-usa-1.hpc-ai.com/v1/completions \
-H "Content-Type: application/json" \
-d '{
"prompt": "Once upon a time",
"max_tokens": 64
}'
#return result
{
"id": "cmpl-c17...6788cd10c0",
"object": "text_completion",
"created": 1758254888,
"model": "/root/highspeedstorage/zhy1/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B",
"choices": [
{
"index": 0,
"text": ", four knots: two left-handed trefoil knots and two right-handed trefoil knots...What is the minimum number of operations required to obtain one left",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"token_ids": null,
"prompt_logprobs": null,
"prompt_token_ids": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 4,
"total_tokens": 68,
"completion_tokens": 64,
"prompt_tokens_details": null
},
"kv_transfer_params": null
}
5. Local Deployment Performance
Measure the generation speed:
time curl https://notebook-38c181af-9501-11f0-a6ea-7ab79f1c53cb-8080.na-usa-1.hpc-ai.com/v1/completions \
-H "Content-Type: application/json" \
-d '{
"prompt": "Explain the theory of relativity",
"max_tokens": 100
}'
Generating 100 tokens of text with the Tongyi-DeepResearch-30B model took approximately 0.535 seconds.