Initially triggered by ChatGPT, the large model boom is continuing to intensify. Tech giants and star startups are scrambling to contribute models for the competitive and diversified commercial market. Among these models, the LLaMA series has accumulated a vast amount of users and practical applications due to its basic capabilities and open ecology. For countless open-source model latecomers, it has become a benchmark model for imitation and comparison.
However, key bottlenecks still exist for AIGC-related enterprises, including questions about how developers can reduce pre-training costs of big models like LLaMA2, as well as how they can build these models practically using continual pre-training and fine-tuning.
As the world's largest and most active community for large model development tools, Colossal-AI provides revolutionary LLaMA2 training efficiency for 8 to 512 GPUs, fine-tuning, and inference solutions. The 70 billion parameter training can be accelerated by 195%, and provides a fully-managed ML cloud platform solution, greatly reducing the cost of large model development and applications.
Open source address: https://github.com/hpcaitech/ColossalAI
LLaMA2 training acceleration of 195%
Meta's open-source large model series, LLaMA, further stimulated the enthusiasm for creating models like ChatGPT, which has inspired the development of many projects and applications.
The latest 7B~70B LLaMA2 model further improves the basic capabilities of the language model. However, since most of the pre-training information for LLaMA2 is derived from English generalized knowledge, the domain information and multilingual capabilities that can be enhanced and injected with fine-tuning are relatively limited. Additionally, high-quality datasets and expertise are typically regarded as core assets of companies and kept in a privatized form. Considering the increase of high-quality private business data, pre-training/fine-tuning the LLaMA2 series of big models efficiently but cheaply is an urgent necessity for many industries and companies. However, LLaMA2 big models only release the original model weights and inference scripts which do not support training/fine-tuning or datasets.
To address the needs mentioned above, Colossal-AI has open sourced a full-flow solution for LLaMA2 with high scalability. This supports models ranging from 7 to 70 billion parameters, while still maintaining good performance from 8 to 512 GPUs.
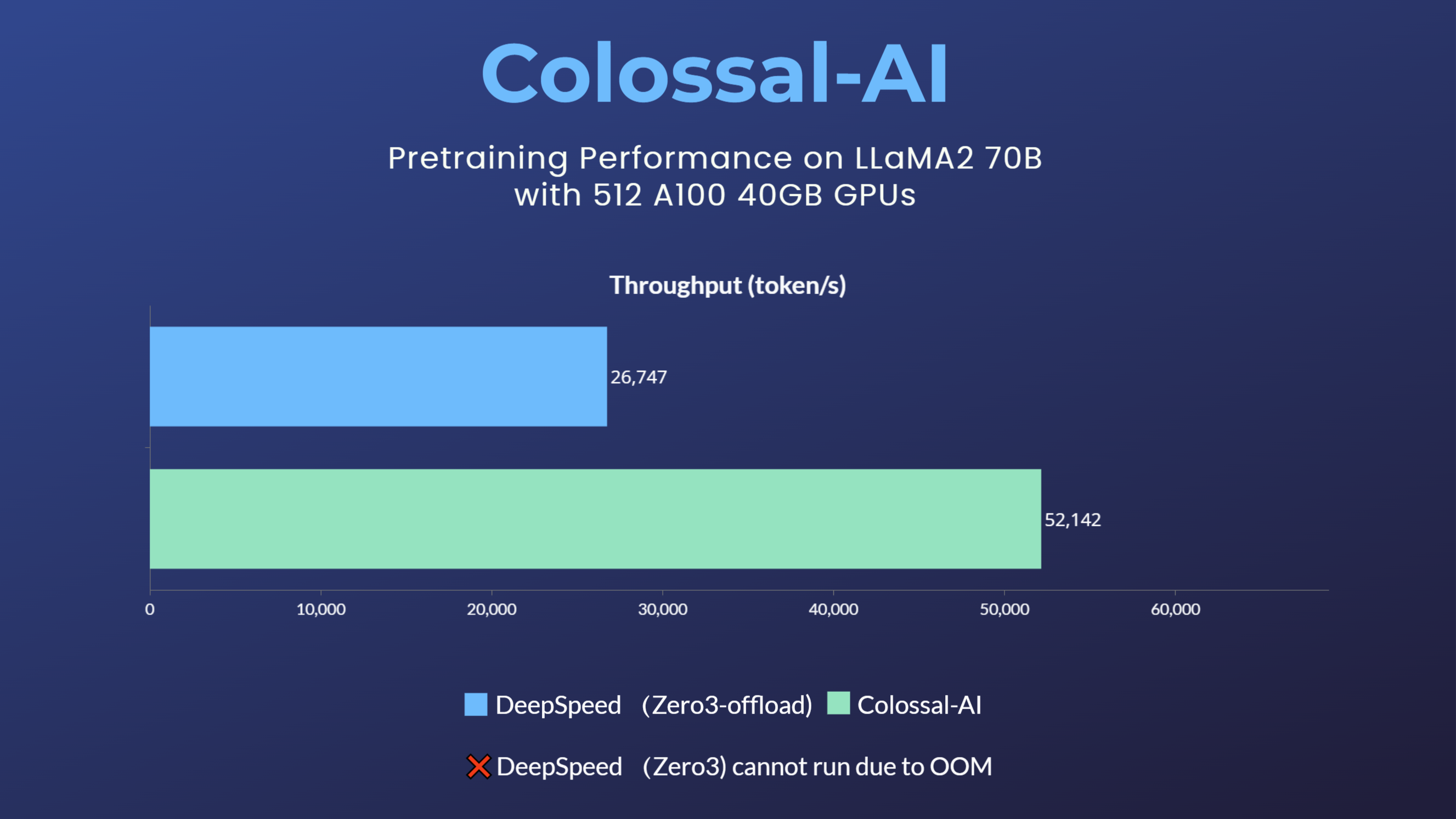
When training/fine-tuning LLaMA2-7B using 8 GPUs, Colossal-AI is able to achieve an industry-leading hardware utilization (MFU) of about 54%. As for pre-training, when LLaMA2-70B was pre-trained with 512 A100 40GB, the DeepSpeed ZeRO3 strategy could not be activated due to insufficient GPU memory. This strategy could only be activated using ZeRO3-offload with a large speed decay. Colossal-AI, on the other hand, still maintains good performance and a training speedup of 195% due to its excellent system optimization and scalability.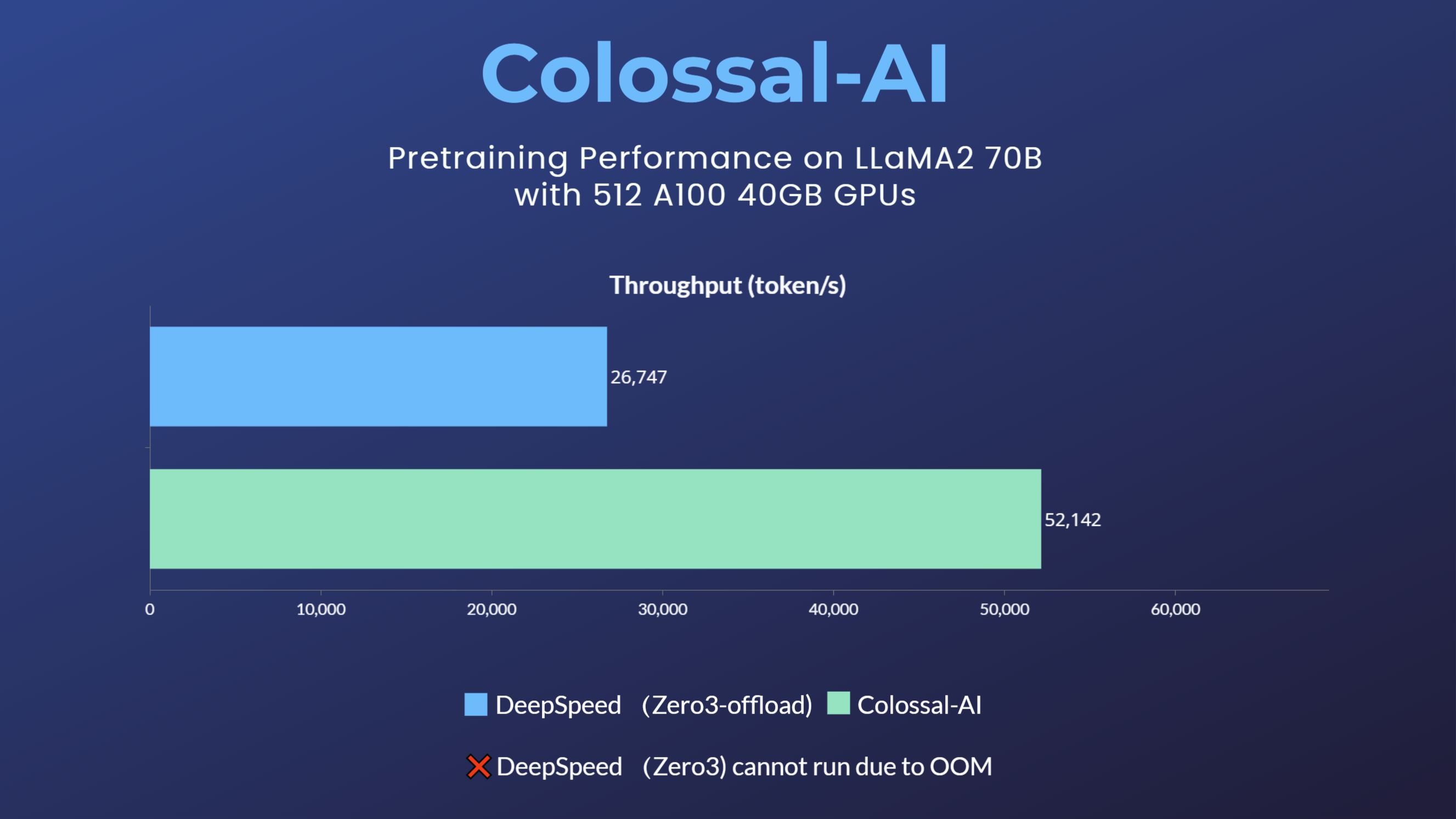
The high performance of Colossal-AI’s LLaMA-2 training/fine-tuning comes from system optimizations such as the new heterogeneous memory management system Gemini, and high-performance operators like Flash attention 2. Gemini provides highly scalable, robust, and easily usable interfaces. Its format, Checkpoint, is also fully compatible with HuggingFace, reducing usage and conversion costs. It is more flexible for cuts, offloads, etc., covering more hardware configurations for LLaMA-2 training/fine-tuning tasks. All of these advantages can be used with just a few lines of code:
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin
plugin = GeminiPlugin()
booster = Booster(plugin=plugin)
model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
ShardFormer Multidimensional Fine-Grained Parallelism
Although Colossal-AI’s Gemini already performs well for a mainstream hardware model, for some extreme hardware conditions or special models, fine-grained optimizations with multi-dimensional parallelism may be needed. Other existing solutions usually require veterans in distributed systems to manually refactor and tune the code to scale, but Colossal-AI's ShardFormer provides incredible multi-dimensional parallelism and operators optimization capabilities. This can be utilized with a few lines of code while providing good performance on both a standalone server/large-scale clusters.
from colossalai.booster import Booster
from colossalai.booster.plugin import HybridParallelPlugin
from transformers.models.llama import LlamaForCausalLM, LlamaConfig
plugin = HybridParallelPlugin(tp_size=2, pp_size=2, num_microbatches=4, zero_stage=1)
booster = Booster(plugin=plugin)
model = LlamaForCausalLM(LlamaConfig())
model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
Colossal-AI’s ShardFormer supports mainstream open source models including LLaMA1/2, BLOOM, OPT, T5, GPT-2, BERT, GLM, etc. Huggingface/transformers models can be imported directly. The Checkpoint format is also fully compatible with HuggingFace, greatly improving the usability compared to Megatron-LM and other projects that require lots of rewritten code.
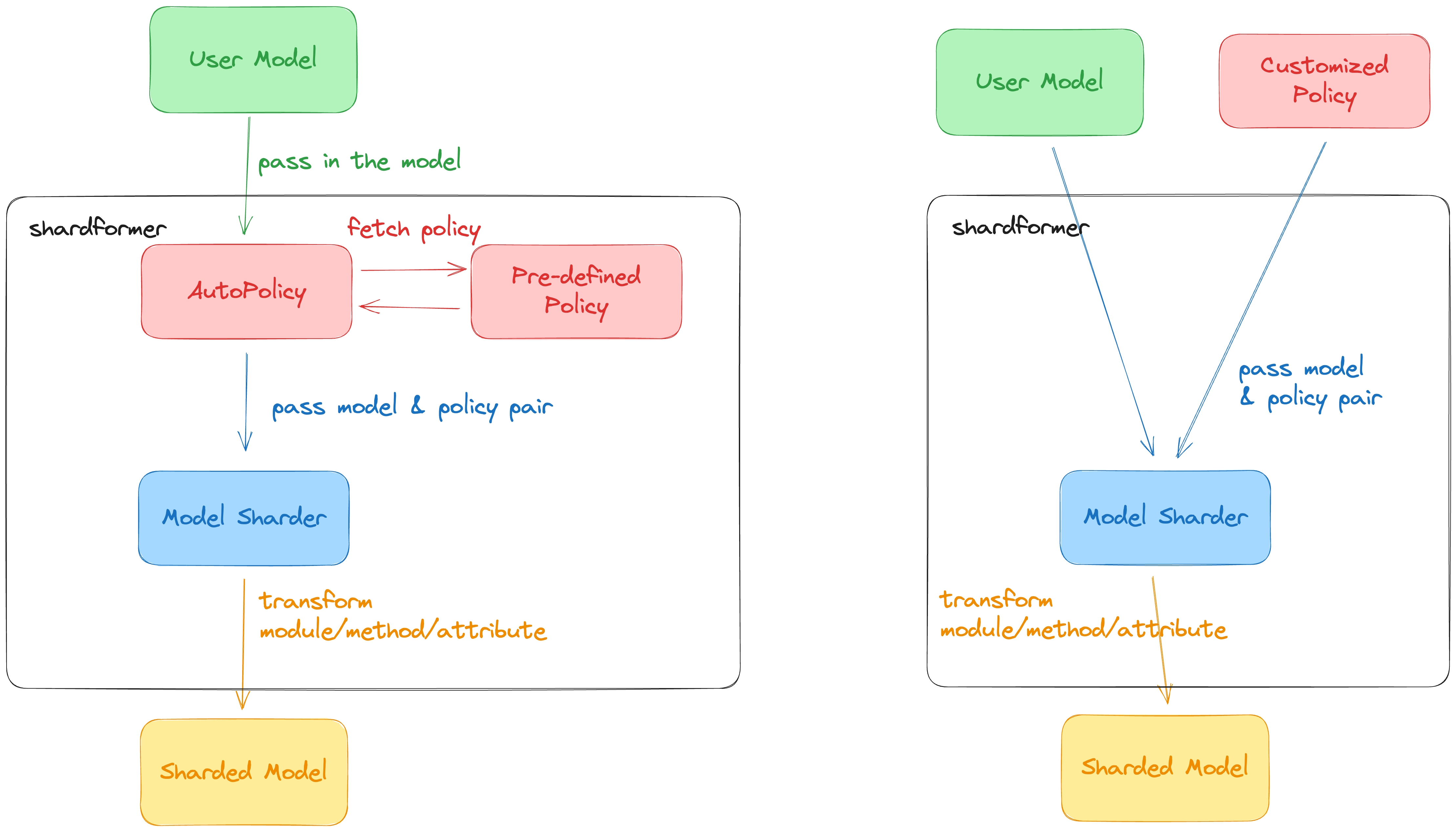
For the parallel strategy, it has supported the following multiple parallel methods: tensor parallelism, pipeline parallelism, sequence parallelism, data parallelism, Zero data parallelism, etc. It can even combine multiple parallel methods to adapt to various complex hardware environments/models with simple configuration commands. Furthermore, it has a variety of built-in high-performance operators, eliminating the need for a tedious compatibility/configuration process. These include:
- Flash attention 2
- Memory efficient attention (xformers)
- Fused Normalization Layer
- JIT kernels
Fully-managed ML cloud platform solution
In order to further improve development and deployment efficiency, the Colossal-AI team also combines advantages of the systems above with computational resources to provide the Colossal-AI Cloud Platform. This offers cheap computational power and mainstream AI applications, including dialog big models, multimodal models, biomedicine, etc. The invitation for internal testing is now open.
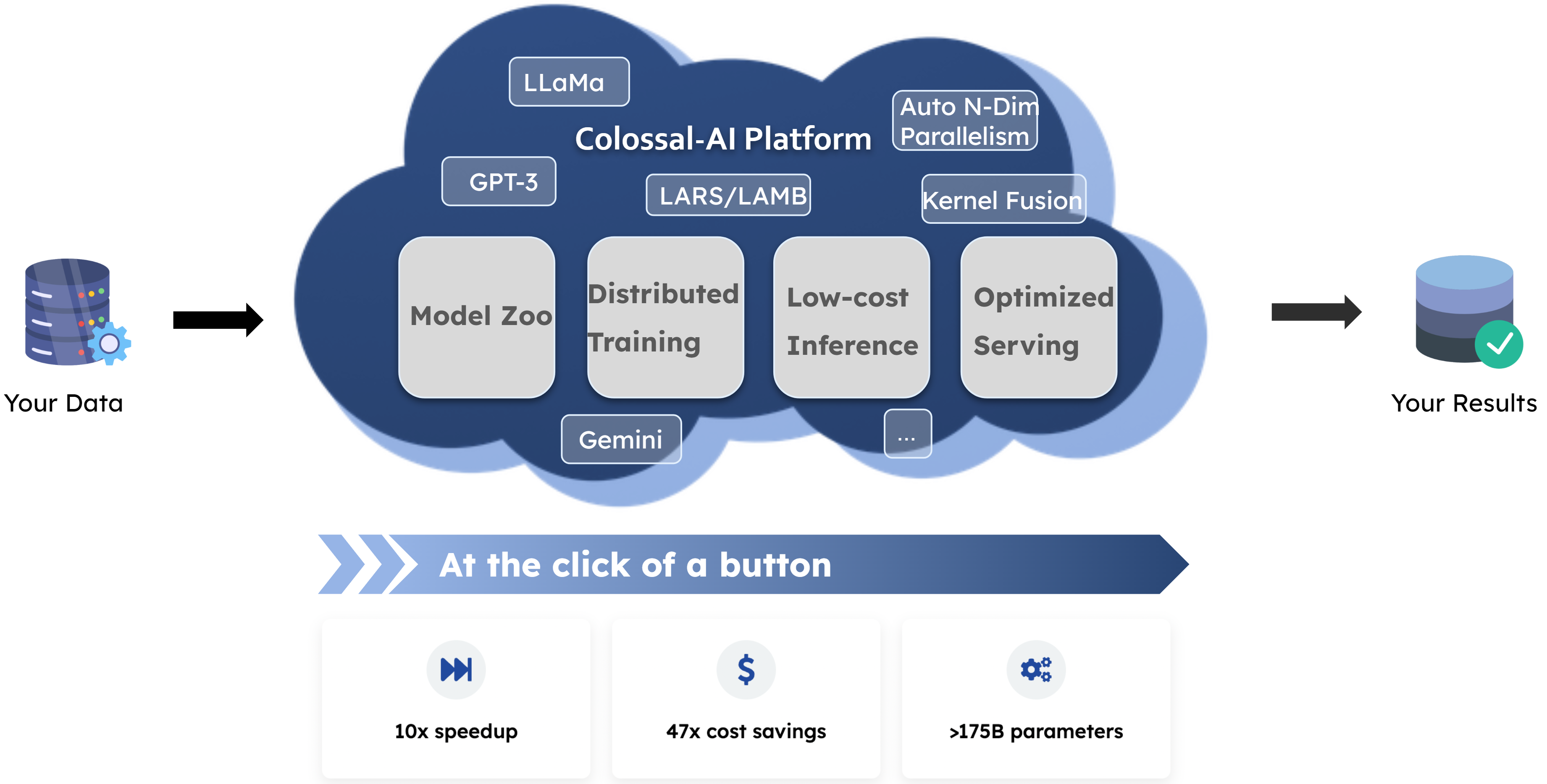
By shielding underlying distributed parallel computing, memory, communication management and optimization of large models, AI developers can focus on the model and algorithm design. This completes the AI model at a lower cost and faster speed, ultimately reducing business costs while increasing efficiency.
Users only need to upload relevant data to train personalized private models without code and can deploy the trained models with one click. The application has been carefully optimized by the Colossal-AI team, and thanks to the optimization of algorithms and systems, the cost of model training and deployment can be reduced immensely.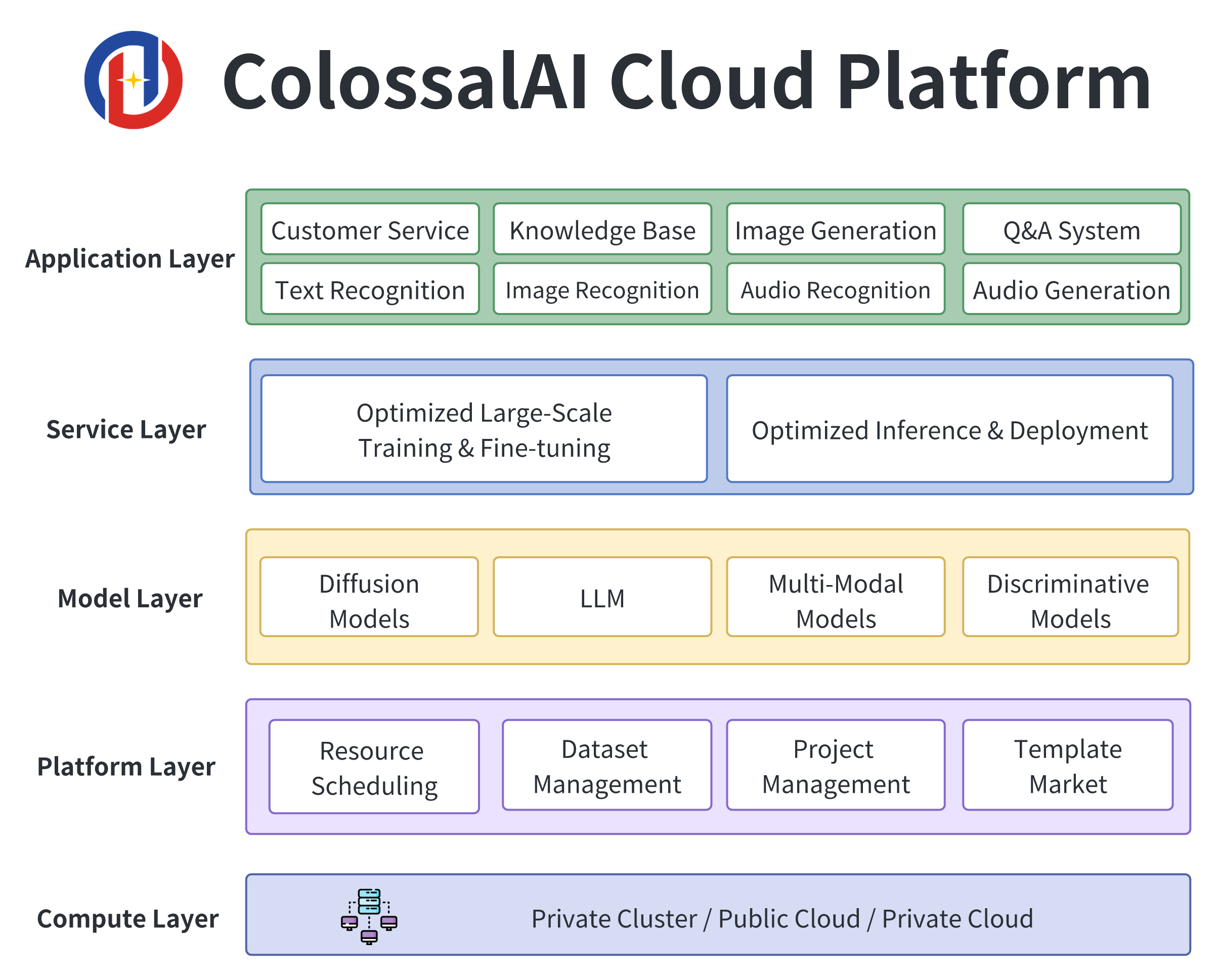
Colossal-AI Cloud Platform: https://platform.colossalai.com/
Colossal-AI open source address: https://github.com/hpcaitech/ColossalAI
Reference
Zhao, Wayne Xin, et al. "A survey of large language models." arXiv preprint arXiv:2303.18223 (2023).
Comments