
What Is Agentic AI? It Could Be the Next Major Shift in Artificial Intelligence
Learn more about the latest breakthroughs in AI technology.
Latest insights, updates, and stories on AI & compute.
Learn more about the latest breakthroughs in AI technology.

Follow along to integrate Kilo Code with HPC-AI Tech easily.

Follow along to integrate Helicone with HPC-AI Tech easily.

Follow along to integrate Hammer AI with HPC-AI Tech easily.

Follow along to integrate Grok CLI with HPC-AI Tech easily.

Follow along to integrate Goose with HPC-AI Tech easily.

Follow along to integrate Flowise with HPC-AI Tech easily.

Follow along to integrate Droid with HPC-AI Tech easily.

Follow along to integrate Dify with HPC-AI Tech easily.

Follow along to integrate Crew AI with HPC-AI Tech easily.

Follow along to integrate Cline with HPC-AI Tech easily.

Join HPC-AI at ICML 2026 in Seoul from July 6–11. Visit Booth #B301 to explore our AI infrastructure platform, exclusive swag, and the ICML Author Incentive Program.

Follow along to integrate AutoGPT with HPC-AI Tech Model APIs.

The full detailed guide to integrate AutoGen with HPC-AI Tech Model APIs.

Step-by-step guide to integrate Aider with HPC-AI Tech Model APIs.

A quick and easy guide to integrate Codex with HPC-AI Tech Model APIs.

Follow along to integrate Claude with HPC-AI Tech and build using your favourite models.

The full guide on how to integrate Cursor with HPC-AI Tech to build with your preferred models in minutes.

Explore the all new GLM-5.2, the latest flagship model from Z.AI, now available on HPC-AI Model APIs.

Recharge your HPC-AI.COM account to unlock next-generation AI infrastructure—and gain the chance to experience world cup live in stadiums around the world.

HPC-AI Model APIs now supports GPT-5.5, Claude Opus 4.7, and Claude Opus 4.6 through a unified OpenAI-compatible API layer, enabling developers to build AI agents, workflow automation systems, coding assistants, and next-generation AI products faster with 40+ native integrations.

At HPC-AI.COM, we are building Model APIs for this new AI ecosystem: flexible, easy to connect, and practical for real workflows. To show what this looks like in practice, we created two demo videos.

HPC-AI.COM announces a CVPR & ICML 2026 Author Incentive Program, rewarding authors with discounted HPC AI Cloud GPU services for their contributions.

We are excited to announce that DeepSeek V4 Pro and DeepSeek V4 Flash are now available on HPC-AI.COM Model APIs, bringing developers access to cutting-edge reasoning and generation capabilities with highly competitive pricing.

Today, the frontier of AI development is defined by agentic readiness—the ability of a model to not just process information, but to execute logic and coordinate complex workflows.

Find out how different LLMs can provide different advantages based on your needs.

Access the Next-Gen GLM 5.1 instantly on HPC-AI Model APIs

Your step-by-step guide on how to integrate OpenCode with HPC's platform.

The full guide on how to integrate OpenClaw with HPC-AI Tech Model APIs platform.

Our Model APIs allow developers to easily access powerful open models through simple APIs build AI-powered applications in minutes.

Find out what are some of the best LLMs for coding available today, and which you should choose.

Partner with HPC-AI to monetize your network. Earn scalable rewards by referring clients to our world-class GPU!

Share your HPC-AI journey and insights with our community, and be rewarded!

Explore how embodied AI systems interact with the physical world, powering robotics and intelligent automation.

Exclusive GPU service discounts for ICLR 2026 accepted authors! Get recharge rewards, stacked benefits for multiple papers, and invite friends for extra computing power vouchers on HPC-AI.COM.
Leverage HPC-AI.COM's upgraded Fine-Tuning SDK for Thinking Machines Lab's Tinker, enabling industrial-scale reinforcement learning with token-based pricing and seamless deployment.

Join HPC-AI.COM's exclusive program for AAAI 2026 and NeurIPS 2025 authors. Access discounted HPC AI Cloud GPU Rental services, recharge rewards, and invite friends for extra benefits.

Join HPC-AI's partner network to transform idle GPU resources into revenue. We connect your enterprise-grade NVIDIA GPUs with global AI developers seeking scalable compute power. Benefit from our robust infrastructure, seamless integration, and dedicated support to maximize your GPU utilization and earnings.

Visit HPC-AI.COM at EMNLP 2025! Explore B200/B300 GPUs, exclusive rewards for authors, and enter giveaways. Accelerate your AI research with our high-performance solutions.

Join HPC-AI.COM's exclusive program for EMNLP 2025 and CVPR 2026 authors. Get discounted HPC AI Cloud services, recharge rewards, and invite friends for extra benefits.

Learn to unleash NVIDIA B200's power for AI on HPC-AI.com. Get started with setup, model serving via vLLM/SGLang, and enjoy FP4 precision for faster, efficient AI workloads.

Discover how to run Qwen3-VL, a cutting-edge multimodal vision-language model, on HPC-AI.COM. Access top-tier performance for visual reasoning, code generation, and more with easy deployment.

Tongyi DeepResearch, the first fully open-source Web Agent rivaling OpenAI's DeepResearch, is now available on HPC-AI Cloud. Access advanced multi-step reasoning and AI research capabilities without complex setup.

In the competitive landscape of artificial intelligence, startups need to innovate at lightning speed without letting infrastructure costs derail their progress. Choosing the right GPU service backbone is a make-or-break decision.

As artificial intelligence and large language models (LLMs) continue to advance, the demand for high-performance GPUs has grown tremendously. NVIDIA’s B200 GPU is one of the latest options designed to accelerate both AI training and inference. In this article, we’ll explore what makes B200 fast, how it compares to GB200, and practical considerations for choosing between buying or renting these GPUs.
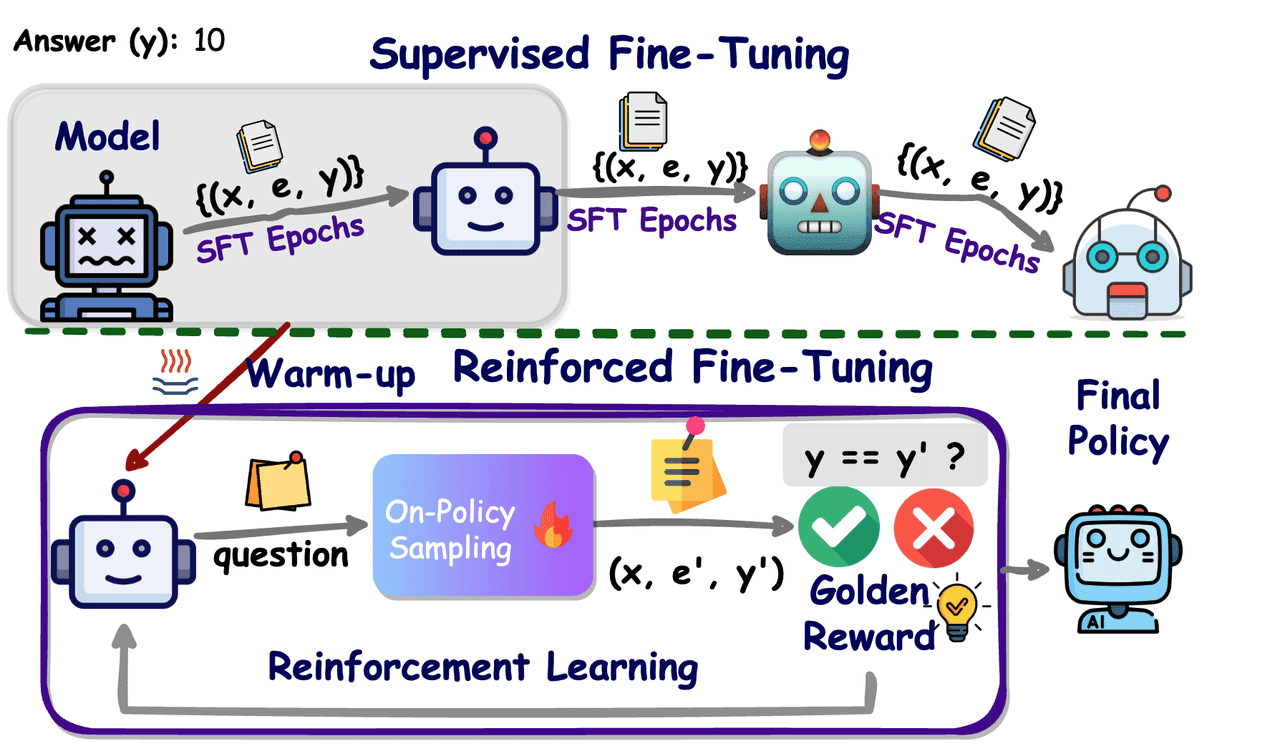
In December of last year, at its product launch, OpenAI first introduced the concept of Reinforcement Fine‑Tuning (RFT), bringing policy‑optimization methods from reinforcement learning into the training of large‑scale language models. Unlike traditional Supervised Fine‑Tuning (SFT), which relies on vast amounts of labeled data, RFT uses reward functions or a verifier to score model outputs in real time and provide feedback, driving the model to iteratively refine its answers and strengthen its reasoning ability.

We’ve deployed NVIDIA Blackwell GPU servers on HPC-AI Cloud Platform with optimized AI-stacks for real-world AI projects. Start now to enjoy the performance gain!

HPC-AI Tech, the company behind the large-model development and deployment platform HPC-AI.COM, has been named to Forbes Asia’s "100 to Watch 2025". The list honors fast-growing companies across the region that are making a strong impact through technological innovation and business success.

At HPC-AI Research Team, we often explore ways to make deep learning models more efficient. One fundamental insight is that deep learning models are inherently sparse—many weights can be safely neglected and zeroed out without significant accuracy loss. This idea, known as model pruning, was first introduced by Yann LeCun in the 1980s through the pioneering work Optimal Brain Damage.

OpenAI has launched gpt-oss-120b and gpt-oss-20b—powerful open-weight language models optimized for reasoning, tool use, and efficient deployment on consumer hardware. These models are released under the Apache 2.0 license, one of the most flexible open-source licenses available, so you can integrate and scale your projects freely.

Although current pre-trained large language models (LLMs) have demonstrated strong generalizability across various tasks, they often underperform downstream natural language processing (NLP) tasks due to the lack of domain-specific knowledge. Retrieval-augmented generation (RAG) [1] emerges to address this challenge by retrieving relevant data from a knowledge base to augment the input prompts of LLMs, thereby enhancing their performance on specific tasks.

Reinforcement Learning (RL) was originally developed for sequential decision-making tasks such as control systems and game strategies, where agents learn by interacting with their environment to maximize long-term rewards.Large Language Models (LLMs) have transformed natural language understanding and generation, yet they still struggle with complex reasoning and multi-step thought processes.

SGLang is one of the fastest inference engines available today. It supports speculative decoding — a technique introduced by Google Research in 2023 and further optimized by frameworks such as SpecInfer, Medusa, EAGLE, and others. This method accelerates model inference **without any loss in output quality.

Reinforcement learning fine-tuning (RFT) is powerful — but let’s face it: it used to be a pain to run. Dual networks, huge memory needs, tons of config files... That’s why we built RUNRL JOB — the easiest way to run RFT workloads like GRPO directly on HPC-AI.COM. No complicated setup. Just pick your model, launch your job, and go.

Reinforcement learning (RL) has transformed how we fine‑tune language models. Traditional approaches like Proximal Policy Optimization (PPO) and Trust Region Policy Optimization (TRPO) use a ‘critic’ value network—doubling model size, memory requirements, and complexity. Meanwhile, human‑alignment methods like Direct Preference Optimization (DPO) optimize for preference, not reasoning.

In 2025, open-source AI is exploding. Meta’s LLaMA 4, the latest in the LLaMA series, is setting new benchmarks for reasoning, multilingual fluency, and tool use. From chatbots to copilots, it's already powering the next wave of AI apps. However, running LLaMA 4 — or any large model at scale often requires time-consuming setup, infrastructure engineering, and DevOps.

We're thrilled to introduce Open-Sora 2.0, a cutting-edge open-source video generation model trained with just $200,000 — delivering 11B parameter performance on par with leading closed-source models like HunyuanVideo and Step-Video (30B). And now, you can fine-tune or run inference with Open-Sora 2.0 instantly — on the HPC-AI.COM GPU cloud, with no contracts, global coverage, and prices starting at just $1.99/GPU hour.

DeepSeek V3/R1 is a hit around the world, with solutions and API services based on the original model becoming widely available, leading to a race to the bottom in pricing and free offerings. How can we stand on the shoulders of the giant and leverage post-training with domain-specific data to build high-quality private models at low cost, enhancing business competitiveness and value?

DeepSeek-R1 is the most popular AI model nowadays, attracting global attention for its impressive reasoning capabilities. It is an open-source LLM featuring a full CoT (Chain-of-Thought) approach for human-like inference and an MoE design that enables dynamic resource allocation to optimize efficiency. It substantially outperforms other closed-source models in a wide range of tasks including coding, creative writing, and mathematics.

We’re thrilled to announce that HPC-AI.COM will be at NeurIPS 2024, and we can't wait to meet you at Booth 55! Whether you're a researcher, developer, or AI enthusiast, we have something exciting for everyone, including cutting-edge GPU solutions, exclusive promotions, and insightful demos.

Recently, the free video generation platform Video Ocean went live, attracting widespread attention and praise. It supports generating videos with any character, in any style, from text, images, or roles. How did Video Ocean achieve rapid updates at low cost? What cutting-edge technologies are behind it?

Singapore-HPC-AI Tech, a startup specializing in AI Software Infrastructure and Video Generation AI, has announced the successful closure of a 50 Million USD Series A funding round. The investors include Singtel Innov8, Sinovation Ventures, Capstone Capital, Greater Bay Area Homeland, Lingfeng Capital, and Stony Creek Capital.
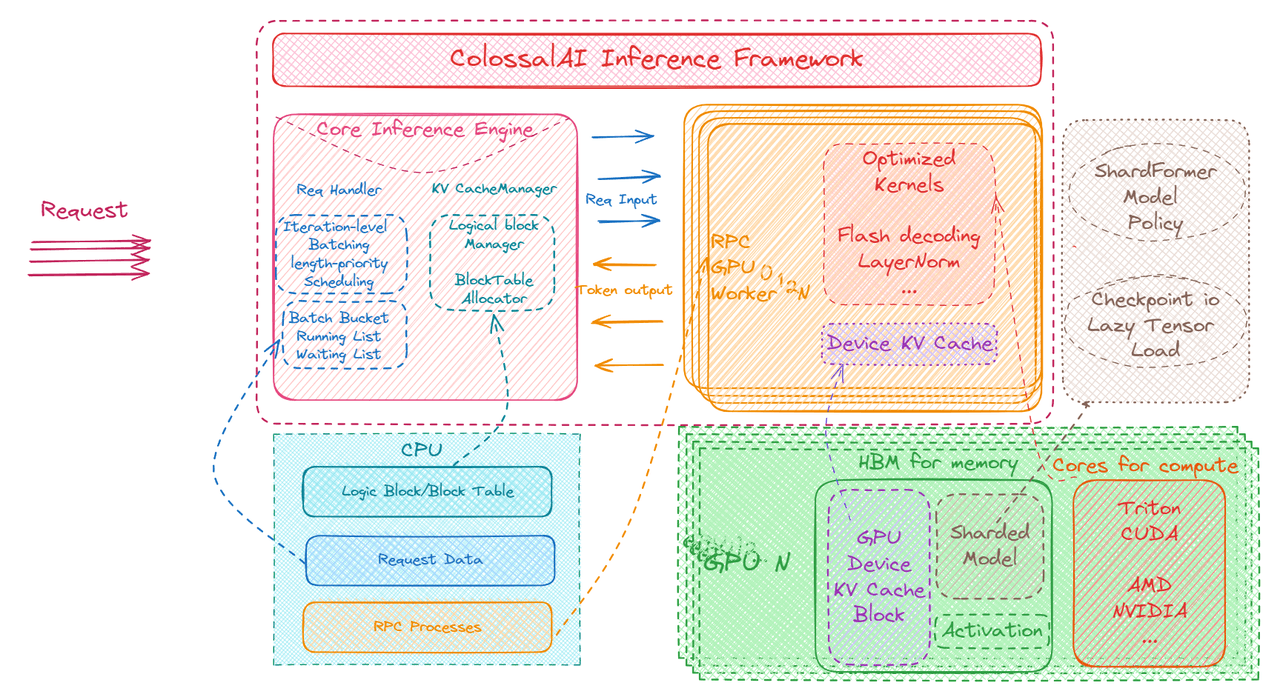
Large AI models have received unprecedented attention in recent years, and have had a profound impact in various application scenarios. Correspondingly, the demand for efficient and highly available large model inference systems is gradually growing, becoming a core challenge for many enterprises.

We are thrilled to announce that we have been selected for the AWS Activate and Google Startup Cloud Program, and have received support including cloud computing resources, AWS/Google Cloud Community, and co-marketing opportunities, etc. This recognition is a huge milestone for us, which will be invaluable to our continued growth and success.

HPC-AI Tech today announced it has joined NVIDIA Inception, a program designed to nurture startups revolutionizing industries with technology advancements. HPC-AI Tech is focused on increasing AI productivity and building a world-class distributed AI development and deployment platform that enables supercomputers and cloud platforms to serve AI at a much lower cost.