How We Made Reinforcement Learning More Efficient with a New Method
The Opportunity and the Challenges
Reinforcement Learning (RL) was originally developed for sequential decision-making tasks such as control systems and game strategies, where agents learn by interacting with their environment to maximize long-term rewards.
Large Language Models (LLMs) have transformed natural language understanding and generation, yet they still struggle with complex reasoning and multi-step thought processes. To address this, researchers increasingly combine RL with LLMs through post-training methods, improving reasoning and alignment with human intent. Techniques like RLHF power models such as ChatGPT, while alignment-driven RL enables systems like Claude. High-profile projects like OpenAI’s O1 and DeepSeek’s R1 have demonstrated the potential of RL-enhanced models.
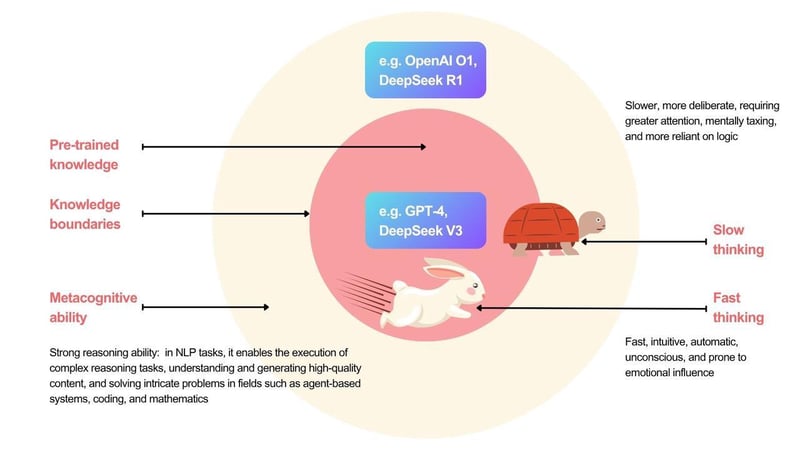
Despite these successes, deploying RL at scale introduces major challenges: general-purpose LLMs have high computational costs, limited domain accuracy, and privacy concerns, while traditional supervised fine-tuning (SFT) depends on costly large-scale labeled datasets and offers limited improvement.
Reinforcement Fine-Tuning (RFT) provides a better alternative—using minimal examples and reward signals to rapidly calibrate behavior, continuously adapt, and reduce labeling costs. Smaller models trained with RFT can even surpass large general-purpose models, cutting inference and deployment costs significantly.
Our Novel Method: Disaggregated RL Architecture
To make this scalable and efficient, we introduced a novel disaggregated architecture. Unlike traditional colocated designs, our approach separates generation and training into different resource clusters, enabling flexible resource scheduling, elastic scaling, and substantially improving efficiency for multi-stage RL workflows.
Producer-Consumer Pattern
Producer-Consumer Pattern is a classic software design pattern used to manage the transfer of resources, data, or tasks between two processes or threads. We extend this design pattern to reinforcement learning (RL) training by implementing a producer-consumer architecture to decouple efficient data sampling from training. This approach supports large-scale, grouped, and adaptive training strategies such as GRPO. Users can flexibly configure the number of inference groups (producers) and training groups (consumers) according to their resource availability, thereby maximizing resource utilization.
-2.png?width=800&height=451&name=1280X1280%20(2)-2.png)
In reinforcement learning algorithms like GRPO, the core training process can be divided into two parts: inference/sampling (rollout) and training. The inference phase interacts with the environment using the current policy model to collect data (rewards), while the training phase updates the policy model using the collected data. In this setup, the inference engine (e.g., vLLM) acts as the producer, pushing data into a shared buffer, whereas the training framework (e.g., Colossal-AI) continuously consumes data from this buffer to efficiently update the policy. The updated model can then be loaded back by the inference engine to begin the next rollout cycle. By using a shared buffer as a bridge, the producer and consumer processes operate independently. Furthermore, asynchronous RL allows these two steps to overlap as much as possible, minimizing resource wastage.
In our training validation experiments on the Qwen2.5-7B model, we verified the reliability of training both mathematics and code tasks. During mathematical training, the model’s reward steadily increased alongside improved performance on the Math500 evaluation. Similarly, in code training, the model’s reward consistently rose in parallel with the scores achieved in coding contests.
-1.png?width=800&height=422&name=1280X1280%20(3)-1.png)
.png?width=800&height=338&name=1280X1280%20(4).png)
Innovation Highlights
Our reinforcement fine-tuning (RFT) approach addresses key challenges that arise when deploying general-purpose large models in real-world business scenarios—such as limited domain understanding, prohibitive costs of ultra-large models, and privacy risks from external service calls.
Key Technical Innovations
Within our RFT framework, we introduce a decoupled architecture leveraging the Producer-Consumer pattern, delivering three major breakthroughs:
- Higher Training Efficiency: Pipeline-based and asynchronous RL strategies allow concurrent execution, dramatically improving training throughput.
- Greater System Flexibility: Resolves resource coupling issues, removes workload bottlenecks, and enables seamless integration with mainstream inference frameworks.
- High Scalability: Supports elastic scaling of training resources, independent tuning for different task types, and compatibility with heterogeneous hardware, maximizing resource utilization.
Our solution delivers an efficient, easy-to-use RL-based fine-tuning framework for large AI models, applicable across a wide range of business scenarios.
Application Examples
This solution is highly versatile and can be applied across many industries, including internet services, e-commerce, manufacturing, energy, finance, and education. Reinforcement learning fine-tuning—where existing models or policies are optimized dynamically through feedback—has proven to deliver strong practical benefits.
Building on our RFT-as-a-Service framework, we developed a fully automated reinforcement learning training pipeline ready for production use. By defining clear reward signals and feeding the model’s own rollout data with explicit feedback, the system automatically generates training data and gradually improves the model’s ability to handle real-world business tasks.
In practical scenarios, the true value of large models is not simply about “giving the right answer” but about “achieving business objectives.” Take e-commerce after-sales customer support as an example: a pre-trained large model might be great at holding smooth conversations but may struggle to effectively resolve issues like “returns and refunds” or “shipping disputes.” Reinforcement learning bridges this gap by evolving the model from being merely conversational to truly actionable.
Example: E-commerce After-sales Support
Here’s how we build the full training workflow for this business case:
Step 1: Define Business Goals and Reward Functions
Reinforcement learning hinges on teaching the model, through trial and error, which behaviors earn rewards. In after-sales support, success isn’t about long chats or perfect grammar, but about:
- Resolving the customer’s issue in one interaction
- Minimizing handoffs to human agents
- Reducing customer complaints
We translate these into measurable rewards:
- Positive rewards:
- Customer explicitly confirms “issue resolved” (+5 points)
- Successfully guides customer to complete a self-service refund (+10 points)
- Keeps conversation under 3 minutes (+3 points)
- Negative penalties:
- Customer asks to be transferred to a human agent (-5 points)
- Model uses evasive language like “I don’t know” or “not sure” (-3 points)
- Customer uses negative words like “bad review” or “complaint” (-8 points)
- Neutral:
- Routine questions about product info or delivery status (0 points)
Step 2: Build a Simulated Training Environment
To train via reinforcement learning, the model needs an environment to interact with. We simulate after-sales conversations by creating:
- User Simulator: A “virtual customer” trained on historical conversation data that can mimic different intents (e.g., “return item,” “request replacement,” “change shipping address”) and emotional states (calm inquiry vs. angry complaint).
- State Representation: Includes current dialogue history (user messages + model replies), user order details (product type, order date, shipping status), and user tags (VIP, new customer, prior complaints).
- Action Space: The possible model responses at each state (e.g., “Please provide your order number so I can check your refund status.”)
Step 3: Optimize the Model with Human Feedback + Reinforcement Learning ( RLHF )
Using data generated from the simulated environment, we refine the model via reinforcement learning. Once it reaches a certain performance threshold in testing, it can be safely deployed. Meanwhile, ongoing user interactions and feedback are collected to continuously improve the model’s effectiveness.
Below is a high-level overview of the simulation environment workflow:
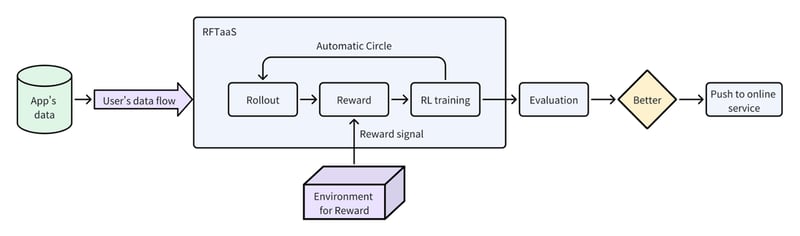
Take the example of improving an agent’s ability to use new tools. For any tool that fails the initial integration test (e.g., under the current model it cannot achieve 99% correct usage), we apply our RFT-based approach to ensure the model learns to use the tool accurately:
- In a simulated environment, the model calls the tool and obtains results through its usage.
- Rewards are assigned based on factors such as the correctness of the tool call and the accuracy of the execution results after a successful call.
- Once the model’s performance reaches the target threshold (e.g., 99%), the tool and the optimized model can be deployed online.
The reward signals are provided by the interactive environment, including scores for correct tool usage and the accuracy of the execution results after successful calls. This process can be tested and validated within the simulation environment. When the model achieves the desired performance level, such as 99%, it confirms the tool’s stability and readiness for deployment.
Conclusion
Our solution delivers immediate, tangible business value by reducing costs and driving measurable impact. On the cost side, RFT minimizes data labeling requirements by using only a small set of examples—cutting annotation effort compared to traditional SFT. It further lowers compute expenses through hardware efficiency and optimized small-model architectures, while automated iterative optimization reduces the need for manual fine-tuning, saving manpower. Beyond cost reduction, RFT enhances business performance by improving core KPIs such as first-contact resolution in customer service and risk detection accuracy in finance. Additionally, small models fine-tuned for specific domains often outperform large general-purpose models, offering greater adaptability and superior results in real-world scenarios.
Reinforcement Fine-Tuning (RFT) transforms large AI models from being simply capable to truly business-driven, bridging the gap between general-purpose intelligence and domain-specific excellence. Whether for e-commerce, finance, industrial operations, or beyond, RFT empowers organizations to achieve faster deployment, lower costs, and higher performance—all with confidence and scalability.
The RFT feature is already integrated into hpc-ai.com, making it easier than ever to leverage RFT for real-world AI applications at scale. And we’re taking it further—an all-new interactive UI is coming soon, giving you an even more intuitive and streamlined experience for building, training, and deploying models.

Ready to accelerate your AI strategy? Explore RFT on hpc-ai.com and start building the future of intelligent, adaptive models today.