SGLang Speculative Decoding Tutorial: How to Deploy DeepSeek Models and Achieve 1.4× Throughput – With Benchmarks
SGLang is one of the fastest inference engines available today. It supports speculative decoding — a technique introduced by Google Research in 2023 and further optimized by frameworks such as SpecInfer, Medusa, EAGLE, and others. This method accelerates model inference without any loss in output quality.
What is Speculative Decoding?
By letting a small model draft tokens and having the LLM only validate them, speculative decoding reduces memory access and boosts inference efficiency, similar to speculative execution in CPUs.
Speculative decoding typically involves two models:
- Verification model: The main model used for inference (e.g., LLaMA, Mixtral, Qwen, DeepSeek).
- Draft model: A smaller model that quickly predicts the output of the verification model to reduce generation latency.
-2.png?width=600&height=465&name=image%20(4)-2.png)
Draft models often require training with information (e.g., logits or distillation) from the verification model. However, DeepSeek-R1/V3 models don't need separate draft models — they are trained with a technique called Multi-Token Prediction (MTP) (also known as next-n prediction). The MTP module can serve directly as the draft model, simplifying deployment.
NOTE: EAGLE, next-n, and MTP are meant for the same thing in the current implementation. Check https://github.com/sgl-project/sglang/blob/69183f8808ec82d55e366324c1fb0564e65366a4/python/sglang/srt/server_args.py#L445-L474 for details.
-3.png?width=1262&height=668&name=image%20(5)-3.png)
Here, we won't dig too much into the speculative decoding or MTP algorithm, but rather provide a detailed tutorial on how to enable speculative decoding for DeepSeek-R1/V3 on HPC-AI.COM using SGLang.
Besides, we provide a reading list if you want to know more about speculative decoding and MTP, please find them in the Reference section.
Step-by-Step Deployment Guide
In this section, we will go through how to install SGLang from source and start the inference server with MTP on HPC-AI.COM.
Note: You may need to create an instance on HPC-AI.COM with sufficient memory (e.g. 8xH200). Instructions here assume access to a Linux-based environment.
Here are some instructions to help you get started:
-
https://www.hpc-ai.com/doc/docs/tutorial/deepseek-v3-inference/
👉 Try it out now on HPC-AI.COM!
Here are the steps:
- Install DeepSeek model weights (Ignore if you have already)
If you are using the Singapore H200 cluster, you can copy the DeepSeek-R1 model from our storage
wget https://dl.min.io/client/mc/release/linux-amd64/mc --no-check-certificate && chmod +x mc && mv mc /usr/bin/mc
mc alias set s3 http://seaweedfs-s3.seaweedfs:8333 readuser hpcai2025 --api s3v4
mc cp -r s3/share/DeepSeek-R1 /root/dataDisk/
Otherwise, you can download DeepSeek model weights directly from HuggingFace
# Install git-lfs (from apt/deb repos)
$ curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
$ apt-get install git-lfs
# Download weights from huggingface
$ git clone https://huggingface.co/deepseek-ai/DeepSeek-R1
# OPTIONAL: If you want to use V3
# $ git clone https://huggingface.co/deepseek-ai/DeepSeek-V3
- Install
SGLang(from source)
# Create conda environment
$ conda create -n py310 python=3.10
$ conda activate py310
# You might also try install using pre-build wheels.
# However, it's better to install from source to
# utilize the most recent updates and optimization
$ git clone https://github.com/sgl-project/sglang.git
$ cd sglang && git checkout v0.4.8.post1
$ pip install -e "python[all]"
- Pre-compile deep-gemm kernels and start the inference engine
# Compile deep_gemm AOT to reduce runtime overhead
$ python3 -m sglang.compile_deep_gemm --model DeepSeek-R1 --tp 8 --trust-remote-code
$ python3 -m sglang.compile_deep_gemm --model DeepSeek-R1 --speculative-algorithm EAGLE --tp 8 --trust-remote-code
# NOTE: MTP with dp attention is available after v0.4.8.post1.
# However, we found it might have some performance issue thus not enabled.
# You can enable it by adding "--enable-dp-attention --dp 8".
# Check https://github.com/sgl-project/sglang/pull/6081
# NOTE: We disable radix attention for benchmarking purpose,
# you might enable it under production environment
# NOTE: We use the default spec args produced by SGLang,
# you can check them at https://github.com/sgl-project/sglang/blob/69183f8808ec82d55e366324c1fb0564e65366a4/python/sglang/srt/server_args.py#L1791
$ python3 -m sglang.launch_server --model-path DeepSeek-R1 --speculative-algorithm EAGLE --trust-remote-code --disable-radix-cache --tp 8 --enable-dp-attention --dp 8
# Wait several seconds for server to boot
# Check the server log until it's ready
# Send example request
$ apt-get install -y curl
$ curl -X 'POST' \
'http://0.0.0.0:30000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "Count from 0 to 1024: ",
"max_tokens": 4096,
"stream": false,
"ignore_eos": false,
"temperature": 1.0,
"top_p": 1.0,
"top_k": 1
}'
Now you can enjoy the power of speculative decoding on HPC-AI.COM.
MMLU Benchmark Results
In this section, we evaluate the impact of speculative decoding with MTP on model accuracy using the MMLU benchmark script provided in the SGLang repository. Our goal is to ensure that the efficiency gains introduced by speculative decoding do not come at the cost of degraded accuracy.
Preparation
The script will help to download MMLU dataset.
$ cd PATH_TO_SGLANG_REPO/benchmark/mmlu
$ bash download_data.sh
Baseline Launch Command:
# start a standalone server
$ python3 -m sglang.launch_server --model-path DeepSeek-R1 --trust-remote-code --tp 8 --disable-radix-cache
# start the benchmark
$ python bench_sglang.py --ntrain 1
# output
'''
Average accuracy: 0.865
'''
Average Accuracy: 0.865
Launch with Speculative Decoding:
# start a standalone server with speculative decoding
$ python3 -m sglang.launch_server --model-path DeepSeek-R1 --speculative-algorithm EAGLE --trust-remote-code --disable-radix-cache --tp 8
# start the benchmark
$ python bench_sglang.py --ntrain 1
# output
'''
Average accuracy: 0.867
'''
Average Accuracy: 0.867
Result
Speculative decoding does not lead to any performance degradation, as demonstrated by the results above (0.865 vs 0.867), though slight divergence may occur due to randomness or implementation.
Throughput Benchmark
In this section, we benchmarked the model throughput under 3 usage scenarios:
- Translation: input tokens and output tokens are similar length, 2048 tokens / 2048 tokens.
- Generation: user input a short paragraph and ask model to generate more, 128 tokens / 2048 tokens.
- Sumarization: user input a long paragraph and ask model to summarize, 2048 tokens / 128 tokens.
For each scenario, we test with 50 prompts under different request rate.
python3 -m sglang.bench_serving --backend sglang-oai --num-prompts 50 --request-rate {rate} --dataset-name random --random-input-len {input_len} --random-output-len {output_len} --random-range-ratio 1
Baseline Launch Command:
python3 -m sglang.launch_server --model-path DeepSeek-R1 --trust-remote-code --tp 8 --disable-radix-cache
Launch with Speculative Decoding:
python3 -m sglang.launch_server --model-path DeepSeek-R1 --speculative-algorithm EAGLE --trust-remote-code --disable-radix-cache --tp 8
Result
Based on the above tests on the 8xH200 cluster, we observed a throughput improvement of up to 1.44×, with a consistent speedup ranging from 1.3× to 1.4× for long decoding tasks such as translation and generation.
Detailed results and corresponding diagrams are presented below:
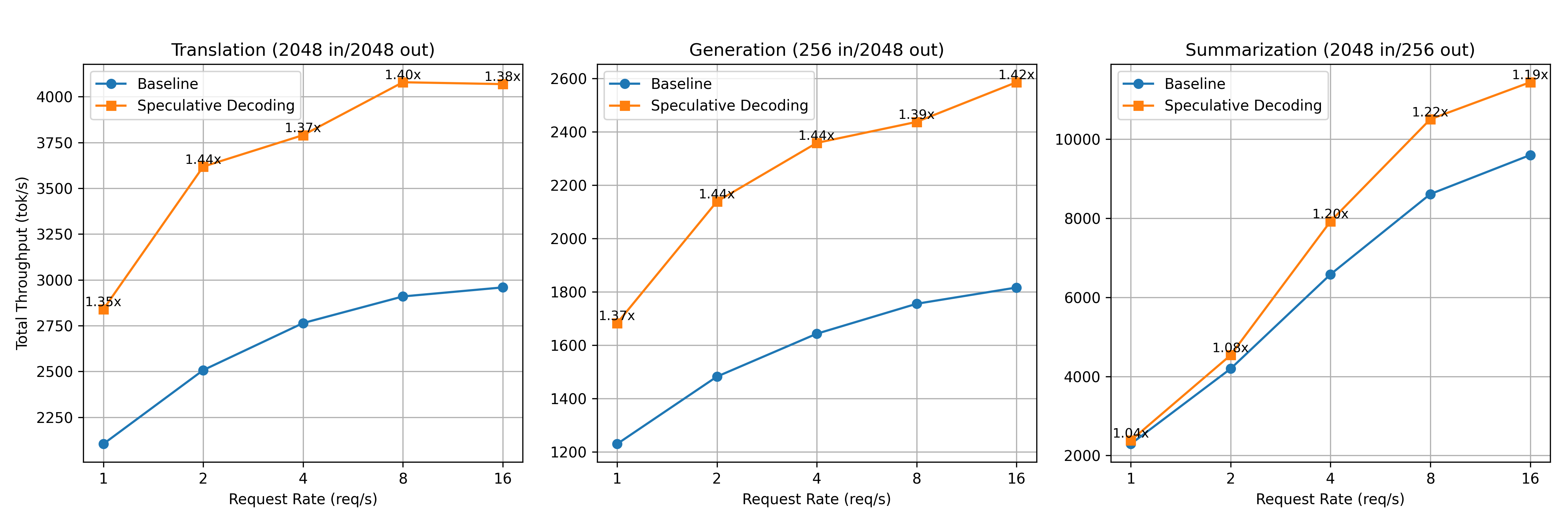
Num Testing Prompts | Usage | Input/Output (tok) | Request Rate (req/s) | Baseline Throughput (tok/s) | Optimized Throughput (tok/s) | Speculative Avg Accept Len (tok) | Speed up |
50 | Translation | 2048/2048 | 1 | 2103.99 | 2838.96 | 2.74 | 1.35x |
2 | 2507.07 | 3618.17 | 2.76 | 1.44x | |||
4 | 2763.92 | 3790.06 | 2.75 | 1.37x | |||
8 | 2909.36 | 4078.73 | 2.76 | 1.4x | |||
16 | 2958.68 | 4068.58 | 2.76 | 1.38x | |||
Generation | 256/2048 | 1 | 1229.89 | 1682.59 | 2.76 | 1.37x | |
2 | 1482.44 | 2138.88 | 2.77 | 1.44x | |||
4 | 1643.16 | 2358.51 | 2.77 | 1.44x | |||
8 | 1755.44 | 2437.26 | 2.77 | 1.39x | |||
16 | 1816.31 | 2585.90 | 2.78 | 1.42x | |||
Summarization | 2048/256 | 1 | 2292.49 | 2380.17 | 2.78 | 1.04x | |
2 | 4195.63 | 4539.54 | 2.78 | 1.08x | |||
4 | 6581.93 | 7922.97 | 2.78 | 1.2x | |||
8 | 8612.76 | 10506.08 | 2.78 | 1.22x | |||
16 | 9599.30 | 11440.65 | 2.78 | 1.19x |
Conclusion: Smarter Inference Starts Here
Speculative decoding is a powerful technique for accelerating large language model inference at scale. At HPC-AI.com, we’re here to support your AI journey—whether it’s through sharing state-of-the-art technologies or enabling features that simplify your model training and deployment. If you're looking to boost performance, don’t hesitate to reach out at service@hpc-ai.com—we’d be happy to help.
With HPC-AI.com, you can deploy high-performance inference services that fully leverage speculative decoding and other cutting-edge optimizations.
Reference
Some well-known speculative decoding papers:
Leviathan, Y., Kalman, M., Matias, Y. (2022). Fast Inference from Transformers via Speculative Decoding. arXiv preprint arXiv:2211.17192.
Cai, T., Li, Y., Geng, Z., Peng, H., Lee, J.D., Chen, D., Dao, T. (2024). Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads. arXiv preprint arXiv:2401.10774.
Miao, X., Oliaro, G., Zhang, Z., Cheng, X., Wang, Z., Zhang, Z., Wong, R.Y.Y., Zhu, A., Yang, L., Shi, X., Shi, C., Chen, Z., Arfeen, D., Abhyankar, R., Jia, Z. (2023). SpecInfer: Accelerating Generative Large Language Model Serving with Tree-based Speculative Inference and Verification. arXiv preprint arXiv:2305.09781.
Li, Y., Wei, F., Zhang, C., Zhang, H. (2025). EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test. arXiv preprint arXiv:2503.01840.
Speculative decoding survey:
Xia, H., Yang, Z., Dong, Q., Wang, P., Li, Y., Ge, T., Liu, T., Li, W., Sui, Z. (2024). Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding. arXiv preprint arXiv:2401.07851.
DeepSeek-V3 technical report (refer to Chapter 2.2 for MTP)
DeepSeek-AI, Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., etc. (2024). DeepSeek-V3 Technical Report. arXiv preprint arXiv:2412.19437.
Docs
HPC-AI.COM Documentation. QuickStart. https://www.hpc-ai.com/doc/docs/quickstart/