Interactively Boost Your Model Performance with Reinforcement Fine‑Tuning
In December of last year, at its product launch, OpenAI first introduced the concept of Reinforcement Fine‑Tuning (RFT), bringing policy‑optimization methods from reinforcement learning into the training of large‑scale language models. Unlike traditional Supervised Fine‑Tuning (SFT), which relies on vast amounts of labeled data, RFT uses reward functions or a verifier to score model outputs in real time and provide feedback, driving the model to iteratively refine its answers and strengthen its reasoning ability.
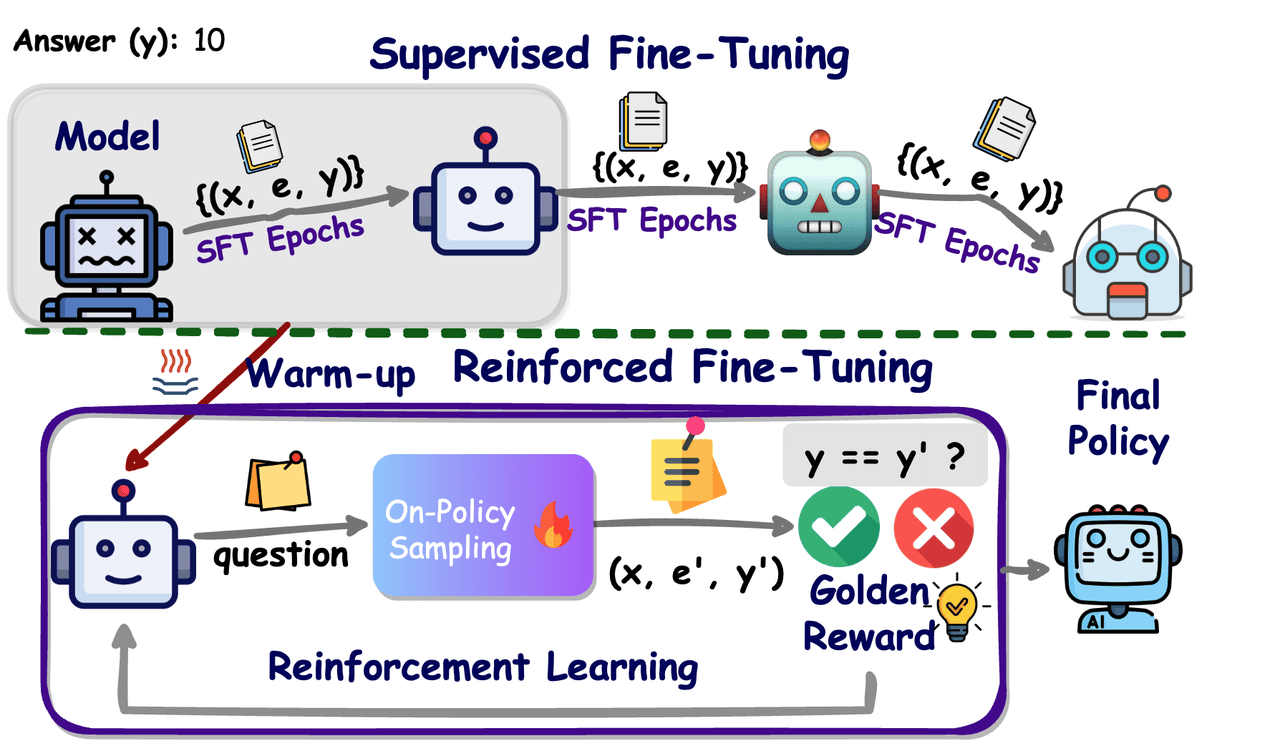
Applications and Benefits of Reinforcement Fine‑Tuning (RFT)
Reinforcement Fine‑Tuning is especially well suited to tasks where a clear standard answer exists, since the correct answer can be used directly to design the reward function or build a verifier. For example:
-
Medical diagnosis becomes more reliable when each recommendation step gets scored against established clinical guidelines.
-
Legal contract review improves dramatically when the system can validate consistency with contractual clauses.
-
Math problem solving benefits from formula-based checks and numerical validation, while code generation can leverage the simple pass/fail nature of unit tests as immediate feedback.
With reinforcement learning algorithms such as Proximal Policy Optimization (PPO), RFT requires only a small number of high-quality examples, often just one-tenth of what SFT needs, and a well-defined scoring criterion to quickly turn a model into a domain expert. This approach provides stronger robustness and deeper reasoning on new challenges while substantially cutting data collection and labeling costs.
1. Key Reinforcement Fine‑Tuning Algorithms
In the reinforcement fine-tuning process, reinforcement learning algorithms play a key role and directly influence the model's final performance. Let's look at several widely adopted algorithms: PPO [2], GRPO [6], DAPO [3], and RLOO [5].
(1) Proximal Policy Optimization (PPO)
PPO is one of the most commonly used algorithms in reinforcement fine‑tuning. It performs limited updates to the policy, ensuring stability and preventing large, destabilizing changes.

This clipping approach in PPO works because it prevents the model from making drastic policy changes that could hurt performance. The model can still learn and improve, but it does so in controlled steps.
(2) Group Relative Policy Optimization (GRPO)
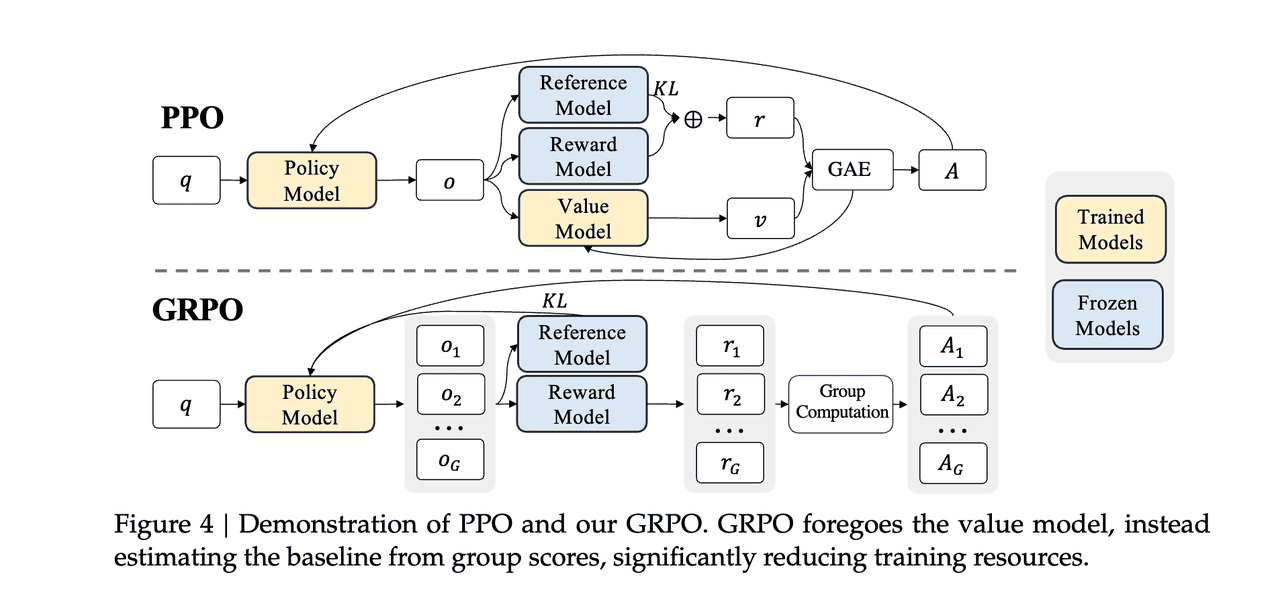
GRPO differs from PPO only in how it computes the advantage $\hat A_t $. Instead of using a learned value function and GAE, it samples a small group of$N$outputs for each prompt and normalizes their rewards.

By normalizing rewards within each group, GRPO sidesteps the need for a separate critic and often yields more stable advantage estimates compared to standard GAE.
(3) Dynamic Sampling Policy Optimization (DAPO)
DAPO extends GRPO by decoupling the lower/upper clipping bounds and adding a dynamic‐sampling step to avoid zero‐gradient groups. While GRPO estimates advantages by normalizing group‑level rewards and applies a symmetric clip plus optional KL penalty, DAPO introduces four major innovations to address GRPO’s instability and inefficiencies:

(4) RLOO (REINFORCE Leave-One-Out)
RLOO is a critic‑free approach to reinforcement fine‑tuning. Its main idea is to remove the critic model used in PPO, thereby saving a substantial amount of GPU memory. Without a critic, RLOO estimates advantages by sampling $N$ responses for each prompt and applying a leave‑one‑out baseline, subtracting the average reward of the other $N-1$ samples from each response’s own reward.

2. Step-by-Step Deployment Guide
(1) How to use Fine-Tuning function on HPC-AI.COM? (Recommended)
Our reinforcement fine-tuning function consists of 7 simple steps that guide you from model selection to deployment. This comprehensive workflow ensures a smooth experience for fine-tuning your models with state-of-the-art reinforcement learning algorithms.
To use our Fine-Tuning function, begin by logging in to HPC-AI.COM and navigating to Fine-Tuning from the left sidebar, then select Fine-Tune a Model to start the process.
Once you are in the interface, you can choose from our currently supported model templates, which include Qwen 3 - 4B, Qwen 3 - 8B, Qwen 3 - 14B, LLaMA 3.2 - 3B - Instruct, and LLaMA 3 - 8B - Instruct.
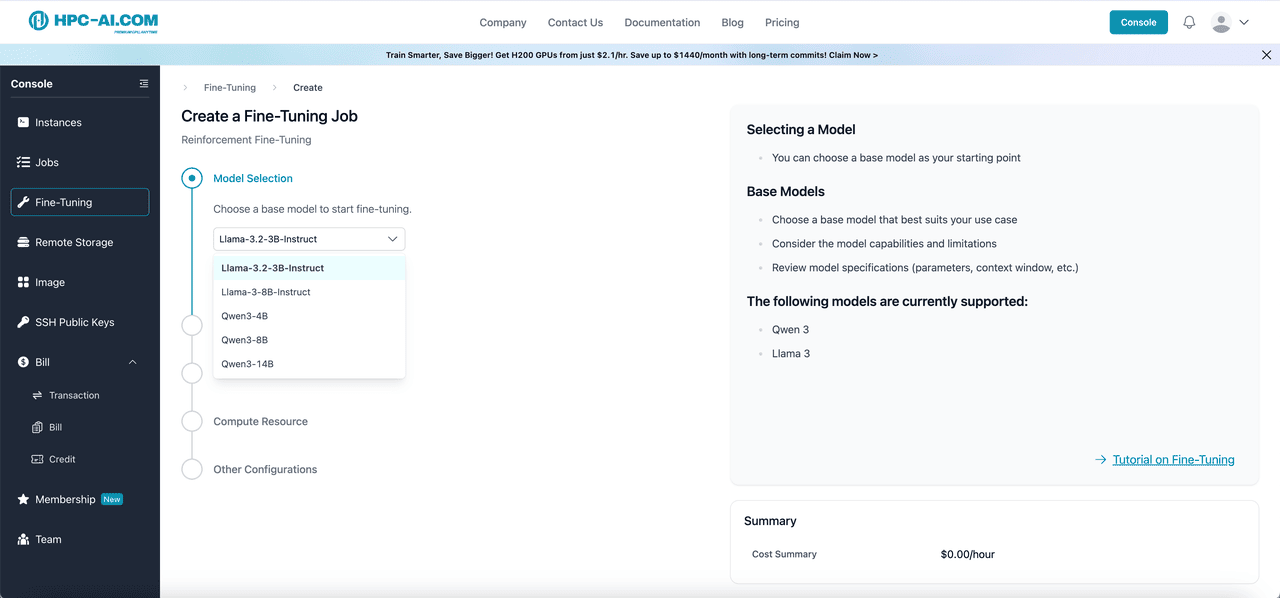
All model templates offer the flexibility to select from four reinforcement learning algorithms: GRPO, DAPO, Reinforce++ (baseline), and RLOO for reinforcement fine-tuning. If you require additional templates or algorithms beyond these options, please reach out to our team at service@hpc-ai.com.
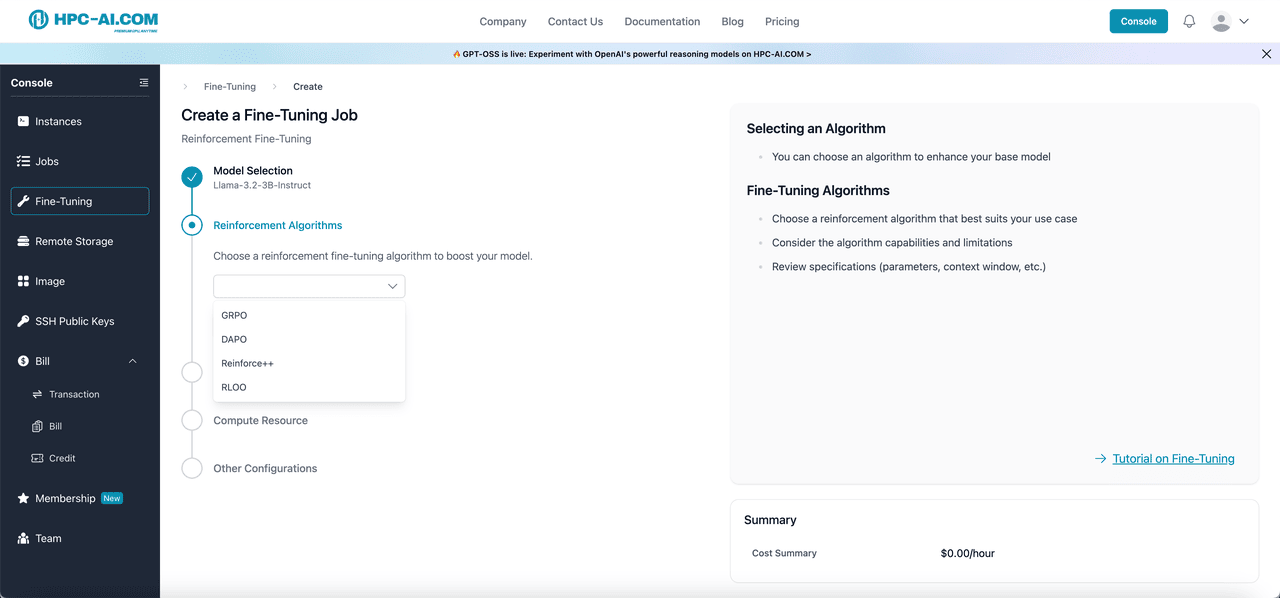
Our platform also supports personalized training data selection and hyperparameter design to ensure your model performs optimally for your specific use case. After submitting your fine-tuning job, you can easily monitor its progress by checking the Job Status section, where a Running status indicates that your job is currently in progress, and once the status changes to Succeeded, your fine-tuned model will be ready for use.
👉 For more details about using the Fine-Tuning function, please refer to our comprehensive tutorial.
👉 Try it out now on HPC-AI.COM!
(2) How to run RFT tasks directly using high performance GPUs
In this section, we will go through how to install Colossal-AI from source and start run RFT project on HPC-AI.COM.
Note: You may need to create an instance on HPC-AI.COM with sufficient memory (e.g. 8xH200). Instructions here assume access to a Linux-based environment.
👉 Try it out now on HPC-AI.COM!
Here are the steps:
- Step 1: Clone and install Colossal-AI:
First, clone the Colossal-AI repository and install it in editable mode.
git clone https://github.com/hpcaitech/ColossalAI.git
pip install -e .
cd ColossalAI/applications/ColossalChat
pip install -e .
- Step 2: Install additional Python packages:
Now install the extra dependencies needed for RFT:
pip install vllm==0.7.3
pip install ray
pip install cupy-cuda12x
python -m cupyx.tools.install_library --cuda 12.x --library nccl
pip install transformers==4.47.0
# pip install transformers==4.51.0 # update to the version 4.51.0 for Qwen3 training.
- Step 3: Run Experiments
Below are the commands for each RFT algorithm. Replace $DATA_PATH and $MODEL_PATH with your dataset and model locations.
To start a run using the GRPO algorithm, execute:
python rl_example.py --dataset $DATA_PATH --model $MODEL_PATH --algo GRPO -t 2 -i 2 -b vllm
To launch a DAPO experiment, use:
python rl_example.py --dataset $DATA_PATH --model $MODEL_PATH --algo DAPO -t 2 -i 2 -b vllm
For the REINFORCE++ (PPB) baseline, run:
python rl_example.py --dataset $DATA_PATH --model $MODEL_PATH --algo REINFORCE_PPB -t 2 -i 2 -tmbs 8 -b vllm
Finally, to execute the RLOO algorithm, enter:
python rl_example.py --dataset $DATA_PATH --model $MODEL_PATH --algo RLOO -t 2 -i 2 -b vllm
- Step 4: Results on Qwen2.5-3B:
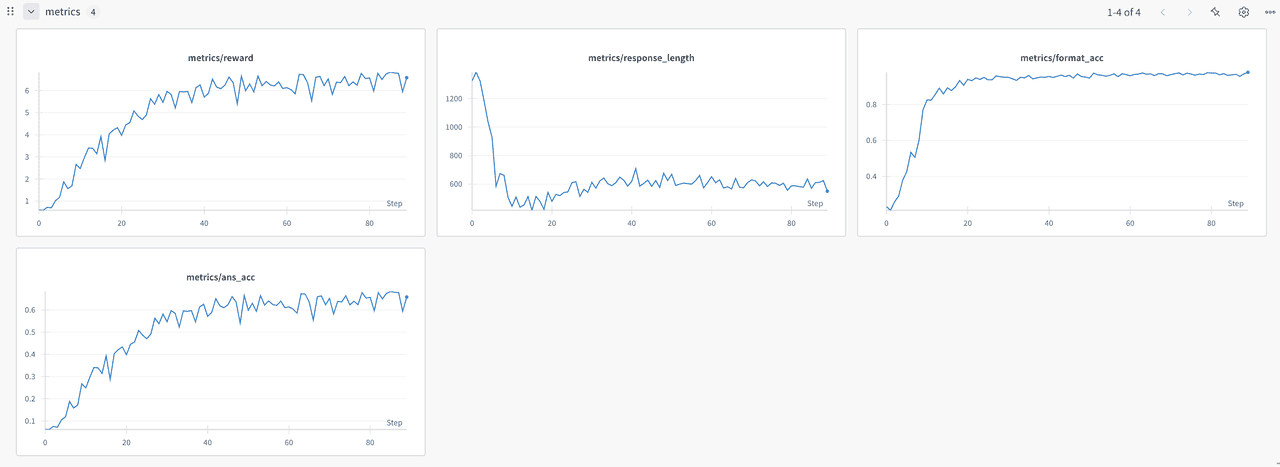
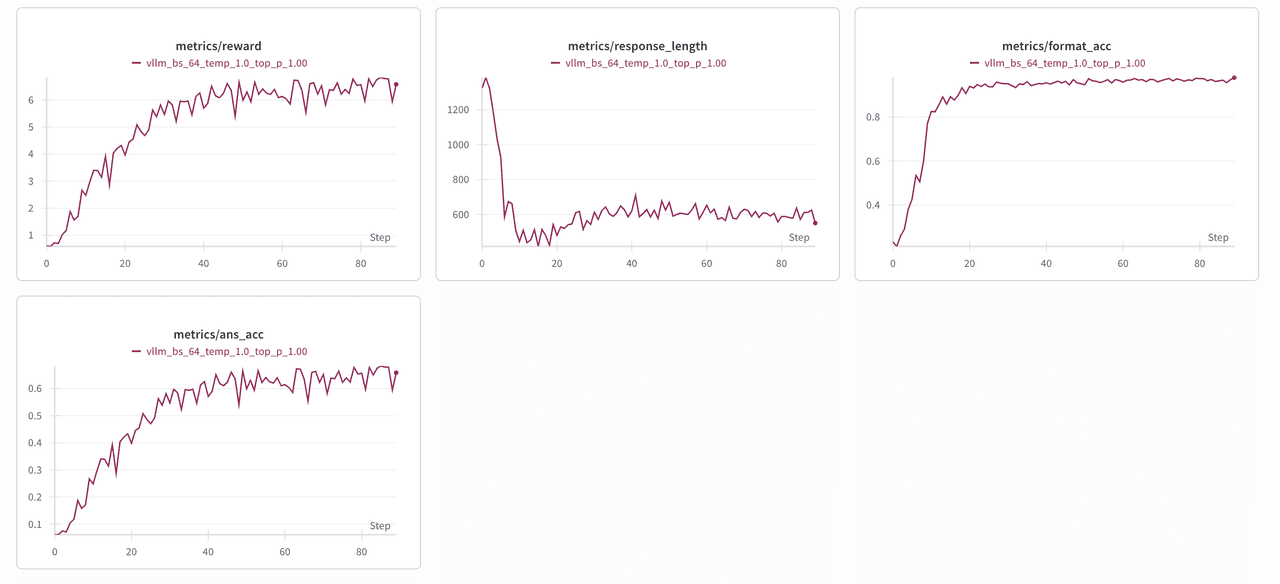
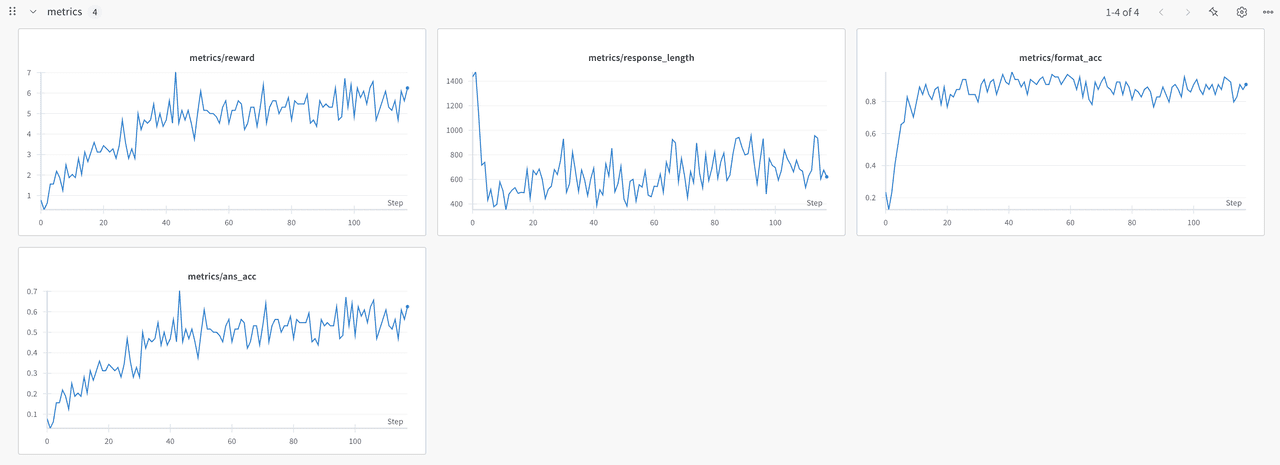
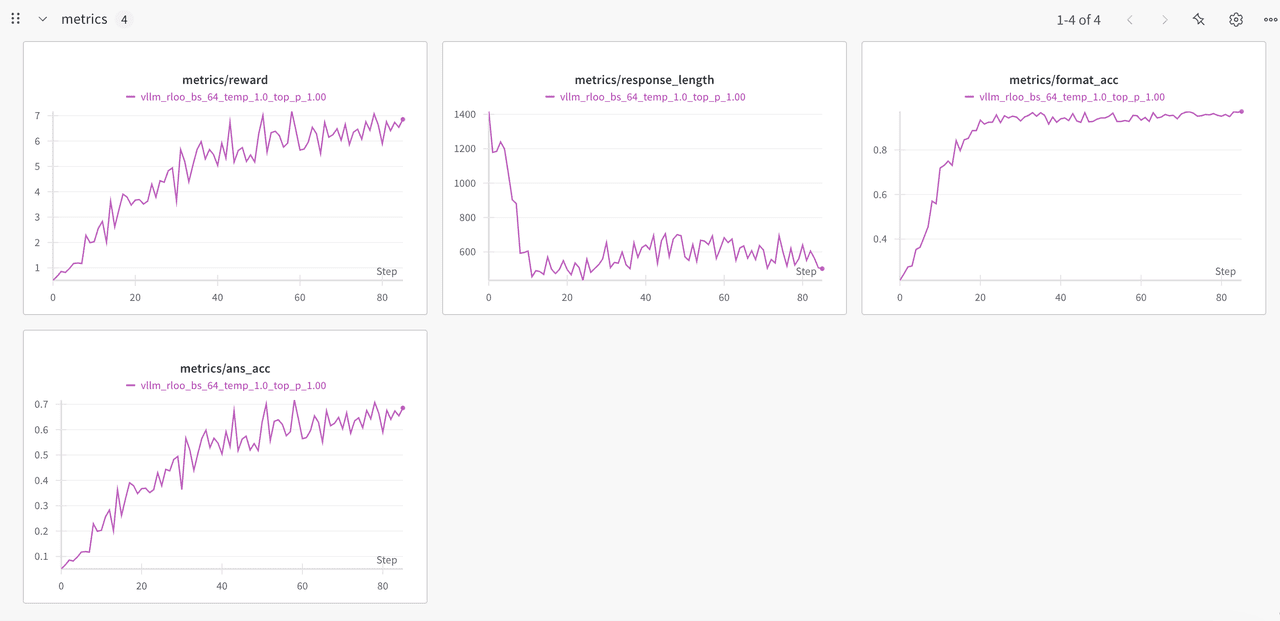
In this section we present the performance of four reinforcement fine tuning algorithms on the Qwen2.5 3B model. We evaluate GRPO, DAPO, REINFORCE_PPB and RLOO by tracking average reward, response length, format accuracy and answer accuracy at each training step. The aim is to show how each method influences learning dynamics and to identify which approach offers the best balance between reward improvement and answer quality.
- (1) GRPO
- (2) DAPO
- (3) REINFORCE++ Baseline
- (4) RLOO
Reference:
[1] Luong, T. Q., Zhang, X., Jie, Z., Sun, P., Jin, X., & Li, H. (2024). Reft: Reasoning with reinforced fine-tuning. arXiv preprint arXiv:2401.08967.
[2] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
[3] Yu, Q., Zhang, Z., Zhu, R., Yuan, Y., Zuo, X., Yue, Y., ... & Wang, M. (2025). Dapo: An open-source llm reinforcement learning system at scale, 2025. arXiv preprint arXiv:2503.14476.
[4] Hu, J. (2025). Reinforce++: A simple and efficient approach for aligning large language models. arXiv preprint arXiv:2501.03262.
[5] Ahmadian, A., Cremer, C., Gallé, M., Fadaee, M., Kreutzer, J., Pietquin, O., ... & Hooker, S. (2024). Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms. arXiv preprint arXiv:2402.14740.
[6] Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., ... & Guo, D. (2024). Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300.
Docs:
[1] https://platform.openai.com/docs/guides/reinforcement-fine-tuning