
As cutting-edge AI models are getting bigger and bigger, the cost of training AI models is getting higher and higher both for enterprises and individuals. Even spending huge amounts of money to use supercomputer clusters or hire experts, it is difficult to train large-scale AI models efficiently.
To address this issue, HPC-AI Tech released Colossal-AI, which aims to build an efficient parallel AI training system, by means of multiple parallelisms, large-scale optimizer, adaptive task scheduling, elimination of redundant memory, reduction of energy loss, etc. As the core of the deep learning framework, Colossal-AI helps users to minimize training costs while maximizing the efficiency of AI training. At present, Colossal-AI is a preview beta version, and the official version will be released in the near future.
Open source address: https://github.com/hpcaitech/ColossalAI
Soaring model parameters and training costs
In recent years, as AI models have evolved from AlexNet, ResNet, AlphaGo to BERT, GPT, MoE …, a distinctive feature of the increasing AI capabilities is the explosive growth of model parameters, which makes the cost of training models also rise sharply. The current largest AI model, GLM Wudao 2.0, has 1.75 trillion parameters. However, just training GPT-3 having 175 billion parameters even takes an NVIDIA V100 GPU about 335 years.
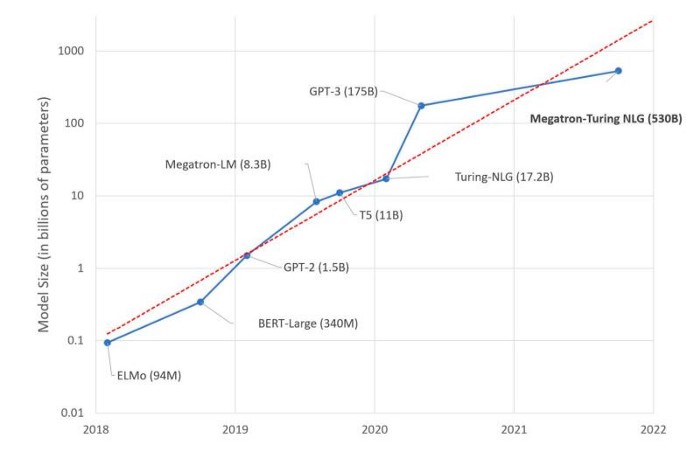
As the capacity of a single machine is no longer sufficient to meet the growing demand for AI training, tech giants have deployed their own supercomputer clusters, such as Google’s TPU Pod and NVIDIA’s SuperPOD, hoping to improve the training efficiency of AI model by scaling the training process to thousands of machines. But the supercomputer still faces the bottleneck that efficiency cannot be further improved when the hardware stack reaches a certain amount, and a lot of computing capacity is wasted. In addition, distributed training, especially model parallelism, often requires domain expertise in computer system and architecture, which further raises training costs.

Colossal-AI

Colossal-AI serves as the core of deep learning frameworks to bridge AI applications and hardware. It improves the training efficiency by means of multiple parallelisms, large-scale optimizer, adaptive task scheduling, elimination of redundant memory, reduction of energy loss, etc., and decouples system optimization from the upper application framework, and lower hardware and compiler for easy scaling and usage.
Multiple parallelisms
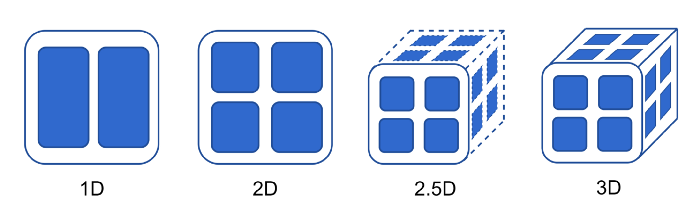
The current mainstream AI parallel solutions, such as Microsoft’s DeepSpeed and NVIDIA’s Megatron, use 3-D parallelism, i.e., data parallelism, pipeline parallelism, and 1D tensor parallelism. With the compatibility of data and pipeline parallelism, Colossal-AI further developed 2D tensor parallelism, 3D tensor parallelism and 2.5D tensor parallelism. In addition, for data such as large pictures, videos, long texts, and long-term medical monitoring, HPC-AI Tech team’s sequence parallelism can distribute the long sequence into sub-sequences over an array of devices, and the model can be trained on a longer sequence which a single GPU cannot accommodate. Therefore, Colossal-AI can increase the parallelism from the current highest 3-dimensional to 5-dimensional even 6-dimensional, which greatly improves the parallel computing efficiency of the AI model.
Large-scale optimizer
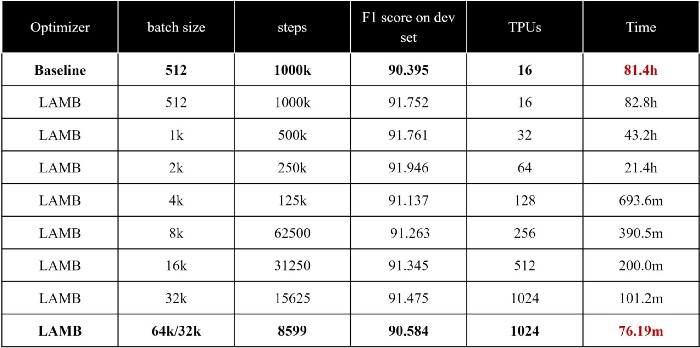
Data parallelism can increase the batch size when training AI models, thereby speeding up the training process. But this usually leads to serious optimization problems, and it is difficult for AI models to maintain capacity. The large-scale optimizers, such as LAMB and LARS, developed by HPC-AI Tech team for the first time expanded the batch size from 512 to 65536, which greatly shortened the model training time while maintaining accuracy. HPC-AI Tech team will further explore new large-scale optimizers based on the profound accumulation in this direction.
Adaptive task scheduling
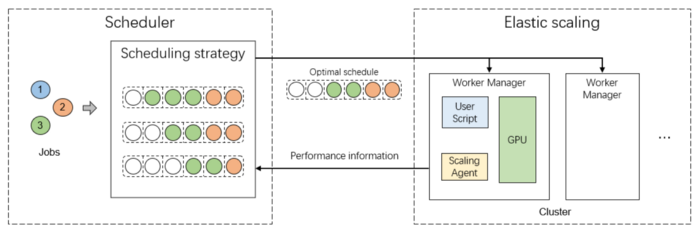
The existing task scheduler mainly judges the task scale based on the number of GPUs, which lacks sufficient flexibility, and the expansion efficiency for AI tasks is poor. The adaptive and scalable scheduler developed by HPC-AI Tech team can elastically expand according to factors such as batch size, and realize efficient task migration through NCCL network communication.
Elimination of redundant memory
Although NVIDIA’s newly released A100 GPU memory capacity has been as high as 80GB, it is still far from enough compared to the cutting-edge AI models having trillions of parameters. In the training process, in addition to the model parameters themselves, gradients, optimizer states, etc. will further seriously consume GPU memory and cannot fully utilize GPU computing capacity. In this regard, Colossal-AI uses zero redundancy optimizer technology to split the optimizer state, gradient, and model parameters, so that the GPU only saves the part needed for current calculations, thereby reducing GPU memory consumption during training and improving GPU utilization. Especially when deploying AI model inference, we can use zero offload to unload the model to CPU memory or hard disk, and use only a small amount of GPU resources to realize low-cost deployment of cutting-edge AI models.
Reduction of energy loss
In distributed training, an important reason for energy consumption is data movement, especially communication between different servers. Colossal-AI allows training using extra-large batches and is able to reduce the number of communications by reducing the number of training iterations. And the multi-dimensional tensor parallelism also greatly reduces the number of communications. For example, with 1000 processors in parallel, each processor needs to communicate with other 999 processors if using 1D tensor parallelism, while in Colossal-AI ‘s 3D tensor parallelism, each processor only needs to communicate with other 9 processors.
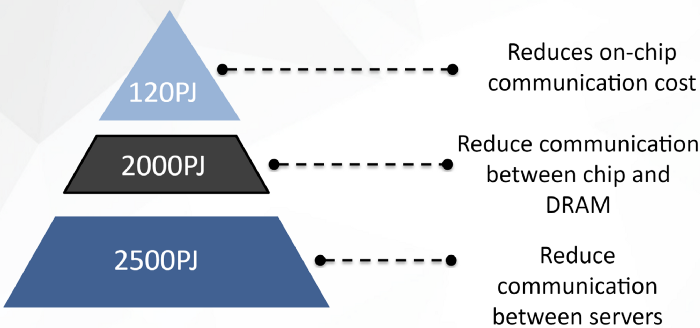
In addition to saving energy costs, because Colossal-AI has improved processor utilization and communication efficiency as a whole, it can complete the training process in a shorter time and consume less computing resources, so it can greatly reduce user training cost and save training time.
Easy to use
Colossal-AI not only provides excellent performance, but also strives for ease of use. It eliminates the need for users to learn complicated knowledge of distributed systems and also avoids complex code modifications. Within small changes, we can quickly use Colossal-AI to scale existing single processor PyTorch code to a cluster with multiple processors, without concern for parallel programming details. Colossal-AI is also compatible with stand-alone operation, facilitating low-cost debugging and inference deployment. And Colossal-AI also provides detailed documentation and common model examples for convenience.
More Features
This release of Colossal-AI is a beta version, and will be updated intensively in the near future based on user feedback and our established plans, we will provide the official version as soon as possible. HPC-AI Tech team will also release several open source subsystems within one year, eventually forming a rich solution for high performance AI platforms to fully meet the different needs of users.
Join Us
The core members of HPC-AI Tech team are from the University of California, Berkeley, Stanford University, Tsinghua University, Peking University, National University of Singapore, Singapore Nanyang Technological University, and other well-known universities in the world. At present, HPC-AI Tech is recruiting full-time/intern software engineers, AI engineers, SaaS engineers, architecture/compiler/network/CUDA and other core system developers. HPC-AI Tech provides competitive salaries.
Excellent applicants can also apply for remote work. You are also welcome to recommend outstanding talents to HPC-AI Tech. If they successfully sign up for HPC-AI Tech, we will provide you with a recommendation fee of hundreds to thousands of dollars.
Resume delivery mailbox: hr@hpcaitech.com
Portal
Paper Address: https://arxiv.org/abs/2110.14883
Project Address: https://github.com/hpcaitech/ColossalAI
Document Address: https://www.colossalai.org/
Reference:
https://github.com/NVIDIA/Megatron-LM
Comments