Would you like to dramatically accelerate large Deep Learning Model training? Would you like to modernize your AI systems stack? Do you finally want a simple, easy to use system that abstracts away all the repetitive nonsense from under the hood?
Fret not, Colossal-AI is now open-source! It’s starting to build its reputation, surpassing state-of-the-art systems from Microsoft and NVIDIA!
Check out the project over here: https://github.com/hpcaitech/ColossalAI

In this rendition of HPC-AI tech’s blog, we’re going to go over why Colossal-AI is necessary in this day and age as well as what makes it special.
Now, onto why a system like Colossal-AI is the natural next step in how we train AI-models.
In this era, innovative AI models are enormously large, and are getting larger and larger year on year. Now, normally this wouldn’t be an issue because as AI models evolve and get larger, hardware gets increasingly better to peacefully accommodate such a change. Unfortunately, lately we have seen a plateauing of both Moore’s law and Dennard Scaling, collectively indicating that the computational capacity of hardware is increasing at a slower pace year on year.
In fact, to illustrate just how dire the situation is, within the context of AI-model training, take a look at the following graph, which pictorially compares how hardware capacities have evolved with how AI-models have evolved.
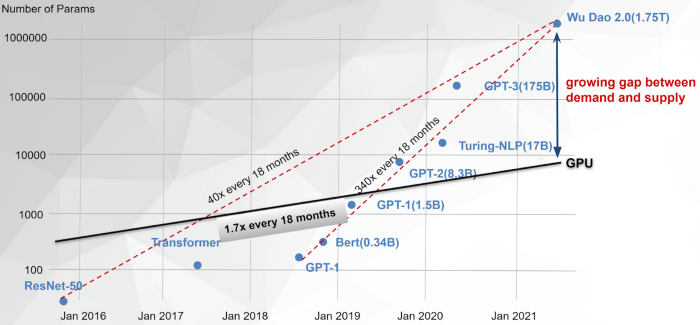
As you can see, though the computational capacities of GPUs are increasing, they simply cannot keep up with the monstrous rate at which AI-models are growing. In fact, it’s getting so ridiculous out there that GPT-3, a model that contains 175 billion parameters, takes the most state-of-the-art GPU: the NVIDIA A100, more than 100 years and $12 million. I don’t know about you, but I would prefer my model to be trained within my lifetime.
All of this, rather resoundingly points to the following paradigm shift: instead of relying on hardware advances to make better machines, why don’t we distribute and parallelize training over multiple machines?
Sounds good in principle, however some AI-models are so exorbitantly huge that enterprises need to expend large amounts of cash to use expensive supercomputers and to hire (even more expensive) experts to distribute the training of these AI-models in a cost-effective manner.
This is where Colossal-AI comes in. Developed by the HPC-AI tech team, Colossal-AI is an efficient AI-model training system that will enable developers to easily train large AI models in a cost-effective manner. It leverages a series of original and innovative ideas at the intersection of machine learning and systems research to accomplish this goal (More on this later).
Since we open-sourced the project, Colossal-AI has been immensely popular on Github(https://github.com/hpcaitech/ColossalAI). Recently, it was ranked the most trending Python project on Github and fifth overall amongst all projects! In part, this is because we have experimentally vindicated the efficacy of Colossal-AI. Compared with existing state-of-the-art solutions from Microsoft and NVIDIA, Colossal-AI can greatly improve training acceleration or maximum model size!
Colossal-AI
Now, let’s move onto the technicalities of the system and delve deep into what makes Colossal-AI easy to use and special. For ease of comprehension, we have segmented the architecture of Colossal-AI into 5 layers. Each layer represents an aspect of Colossal-AI that integrates inventive state-of-the-art techniques to accelerate training (or inference, as is the case with the last layer).

Colossal-AI is a system that sits in between classical DL frameworks (like Pytorch and Tensorflow) and the underlying hardware models are trained on. In doing so, it effectively decouples all the “system level optimizations” (that Colossal-AI affords) from any system that may be used on top of it and the underlying hardware the software is run on. It supports the following features:
- Automatic infinite-dimensional parallelism
- Optimizer Library
- Adaptive task scheduling
- Elimination of redundant memory
It provides the above features in an easy to use, nonetheless customizable, manner. In doing so, the model-trainer can experience a reduction of energy loss and the usual monetary benefit associated with it. You no longer need to be an expert in distributed systems or in machine learning. With minimal code modification, you can easily scale your AI models and deploy them into production.
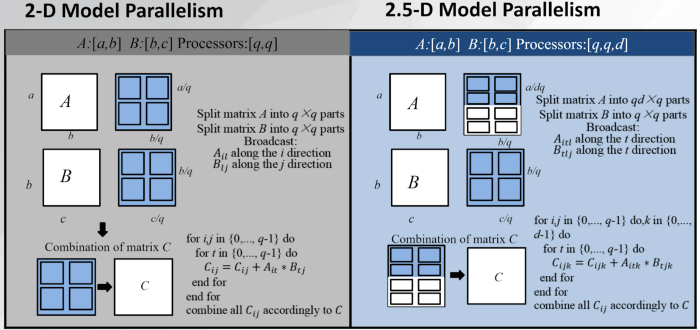
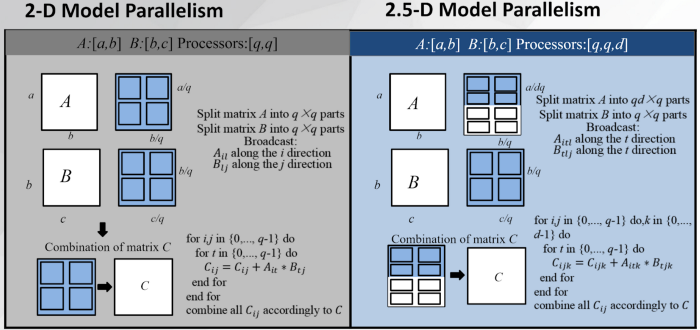
Automatic infinite-dimensional parallelism
Mainstream AI parallel solutions, such as Microsoft’s DeepSpeed and NVIDIA’s Megatron-LM, are restrictive in the types of parallelism that they offer. They limit themselves to only data parallelism, pipeline parallelism or 1D tensor parallelism. Colossal-AI, however, melds these techniques together and additionally provides infinite-dimensional tensor parallelism. Moreover, the HPC-AI tech team has integrated a way to break up large sequential data (like lengthy videos or long pieces of text) and distribute them over several machines, now enabling models that ingest sequential data to be trained over multiple machines when a single machine is insufficient. Parallel training of sequential data is a notoriously difficult problem, Colossal-AI, nonetheless, provides engineers innovative solutions to tackle such issues.
Altogether, Colossal-AI grants engineers higher-dimensional parallelism, greatly improving the utilization of resources by more efficiently using them when training AI-models. Though all of these perks are provided to engineers through simple APIs, Colossal-API retains customizability, allowing the engineer to extend our system to other novel parallelism strategies.
Optimizer Library
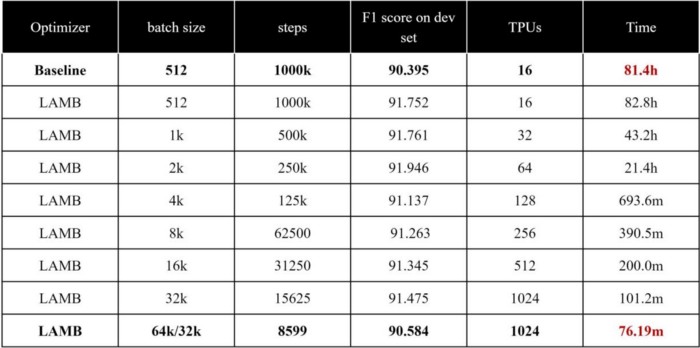
Colossal-AI also provides various optimizers for different situations. In particular, Colossal-AI innovatively solves a large bottleneck that often-times inhibits AI-models to be efficiently parallelized: an inability to scale the batch size. With great implementations of LAMB and LARS optimizers, Colossal-AI can enable the users to easily expand the batch size from 512 to an outstanding 64k. This, in turn, means we can leverage more machines efficiently to reduce training time, without sacrificing accuracy. Just see for yourself, the below table demonstrates how the time taken to finish training of a BERT language model, decreasing training time from 81 hours to a measly 76 minutes.
Adaptive task scheduling
When running multiple jobs across a cluster, scheduling is crucial to reducing turnaround time and increasing the utilization of resources. Existing task schedulers, however, mainly use coarse metrics of tasks, like the number of GPUs a task consumes, resulting in a poor expansion efficiency for AI tasks.
The HPC-AI Tech team has combatted this issue by building an adaptive and scalable scheduler that can elastically expand according to factors such as batch size, as well as realize efficient task migration through NCCL network communication.
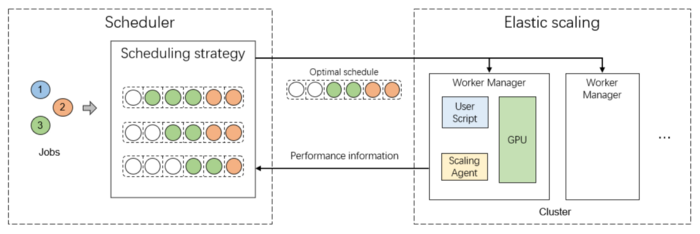
Elimination of redundant memory
With trillion parameter models inexorably proliferating the industry, we can no longer use a single GPU to hold an entire model in-memory. Oftentimes in distributed training, certain parts of the optimizer state may be redundant. To combat this issue, Colossal-AI leverages ZeRO — zero redundancy optimizer — to split the optimizer state, gradient and model parameters, so that machines can save the parts needed for current computations. Particularly, when deploying AI models to production for the purpose of inference or finetuning, engineers can use ZeRO to offload the model to CPU memory, or a hard-disk, and use only a fraction of existing GPU resources to realize low-cost deployment of large state-of-the-art AI models.
Benefits
Now, not only does Colossal-AI allow you to now train large AI-models whilst enjoying incredible speedups over conventional, mainstream, systems. It empowers you, the engineer, to do so in a cost-effective manner — in incurring massive energy and resource savings — as well as in a convenient manner.
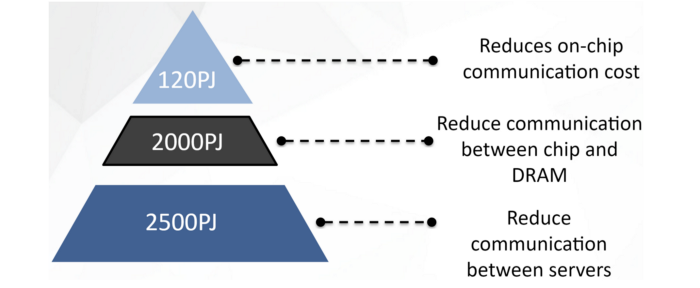
Energy Savings
In distributed training, data movement is an energy consuming behemoth. Colossal-AI induces massive energy savings by: (1) facilitating a greater degree of parallelization thereby increasing the utilization of resources leading to quicker training times, (2) minimizing data movement across distributed and parallel training, primarily achieved through multi-dimensional tensor parallelism. In naive 1D parallelism, if we use 1000 processors in parallel, each processor needs to communicate with 999 processors, whilst in Colossal-AI’s 3D tensor parallelism each processor needs to only communicate with 9 other processors.
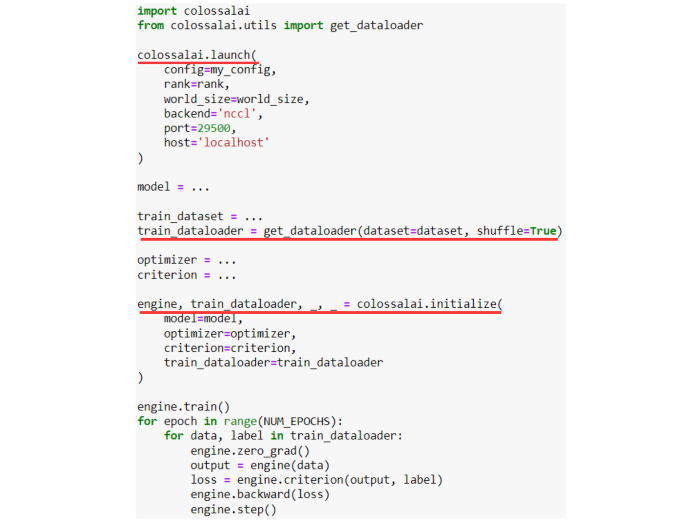
Ease of use
Finally, Colossal-AI grants the engineer all of the above benefits without unnecessary effort and is easy to use. By exposing simple APIs that, under the hood, apply these innovative techniques, Colossal-AI eliminates the need for users to be experts in distributed systems and simultaneously avoids complex code modifications. With small changes to pre-existing codebases, you can use Colossal-AI to scale existing single process code to a cluster with multiple processors, without worrying about parallel programming details. Colossal-AI is also compatible with stand-alone operation, helping low-cost finetune and inference deployment. Just look at how easy it is to quick-start parallel training.
Performance
I know what you’re thinking right about now. The ML field is brimming with people making promise after promise, repeatedly proclaiming that they beat the state-of-the-art with results that aren’t always reproducible. We would thus like to conclude by showing you some experiments that vindicate the power of Colossal-AI.
GPT-3
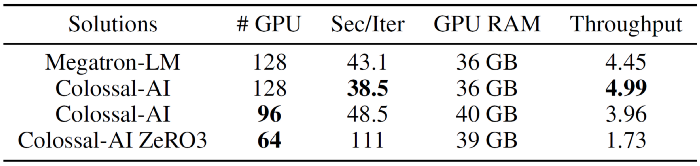
We trained the GPT-3 model, comparing it to NVIDIA’s state-of-the-art Megatron-LM. Colossal-AI can, in comparison, accelerate training by as much as 10.7%, incurring huge benefits to engineering, considering the millions of dollars training such a large model costs! In fact, by eliminating redundant memory storage, we can reduce the number of GPUs used in comparison to Megatron-LM, to 96 whilst maintaining decent speed. Not to mention, when ZeRO3 is turned on, we can further reduce that number to 64, freeing up an extra 64 GPUs for other applications to use!
GPT-2
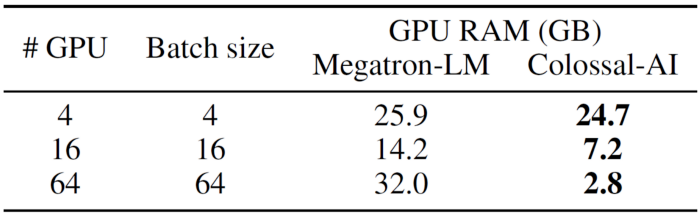
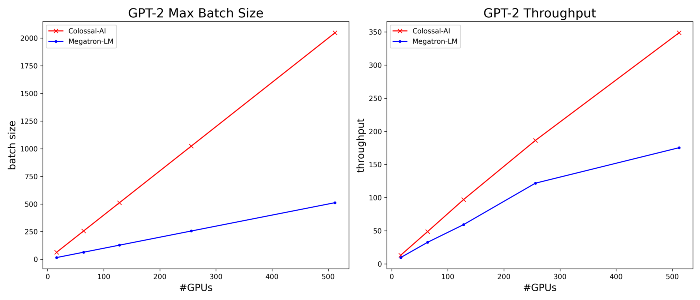
A more common case is GPT2. We can see, yet again, that Colossal-AI triumphs over Megatron-LM! With all of 4, 16 and 64 GPUs, Colossal-AI uses significantly lower RAM, enabling engineers to train larger models and/or larger batch sizes to train models faster.
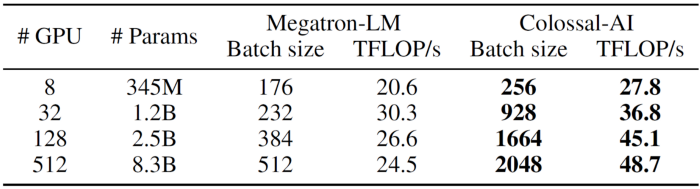
With a larger batch size, Colossal-AI can reach higher resource utilization. For example, the following results show that Colossal-AI achieves an uptrend on teraFlOP/s per GPU, scaled from 8 to 512 GPUs with an increasing model size, which means a superlinear scaling!
ViT
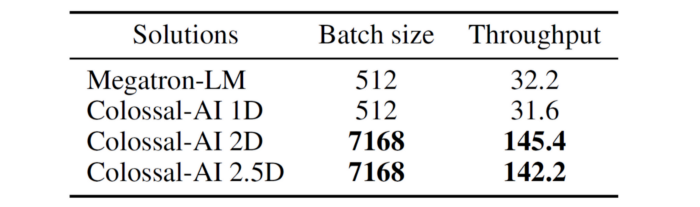
Similarly, on the VIT model, using 64 GPUs, our higher-dimensional tensor parallel method yet again outperforms Megatron. Colossal-AI trains with higher throughput using 2 and 2.5 dimensions, by taking advantage of larger batch sizes.
BERT
Another feature that differentiates Colossal-AI is its capability in effectively utilizing sequence parallelism. For example, on BERT, Colossal-AI’s sequence parallel approach requires less RAM compared to Megatron, enabling the use of larger batches to accelerate the training process. It also allows the developer to use longer sequential data.
Colossal-AI’s approach to sequence parallelism is compatible with pipeline parallelism. When sequence parallelism and pipeline parallelism are used together, developers can furthermore save time when training larger models as there is no split-gather communication overhead between pipeline stages.
The Team
We are HPC-AI Tech and our goal is to allow enterprises and researchers to easily develop their AI products instead of focusing on the sophisticated and cumbersome distributed systems or cloud systems behind them. HPC-AI Technology Inc. was founded by Dr. Yang You, a Presidential Young Professor at the National University of Singapore, who holds a PhD from UC Berkeley. He is now serving as Chairman of HPC-AI Technology Inc. and advising the Colossal-AI team. Our amazing team includes many talented researchers and engineers like Benjamin Brock and Ahan Gupta.


More Features
Colossal-AI is still in the beta testing stage, and more amazing results will be released recently.
If you are looking to scale up your AI models and deploy them into production, we encourage you to check out the code and join our discussion on github. Your feedback is highly appreciated. We will make intensive iterative updates based on users’ feedback and established plans to provide users with the official version as soon as possible.
The Colossal-AI team will also release several open-source subsystems within one year, eventually forming a perfect solution for high-performance AI platforms to fully meet the different needs of users.
Join Us
HPC-AI Tech is a global team and the core members are from the University of California, Berkeley, Stanford University, Tsinghua University, Peking University, National University of Singapore, Singapore Nanyang Technological University, and other top universities in the world. Currently, HPC-AI Tech is recruiting full-time/intern AI system/architecture/compiler/network/CUDA/SaaS/k8s and other core system developers.
HPC-AI Tech provides highly competitive compensation packages. Our staff can also work remotely. You are also welcome to recommend outstanding talents to HPC-AI Tech. If they successfully join HPC-AI Tech, we will provide you with a recommendation fee of thousands of US dollars.
Resume delivery mailbox: contact@hpcaitech.com
Funding
HPC-AI Tech raised 4.7 million USD from top VC firms in just 3 months after the company was founded. For more information, please email contact@hpcaitech.com
Portal
Paper Link: https://arxiv.org/abs/2110.14883
Project Link: https://github.com/hpcaitech/ColossalAI
Document Link: https://www.colossalai.org/
Reference
https://github.com/NVIDIA/Megatron-LM
Comments