
Recently, we published “Pre-training ViT-Base/32 in half an hour, Colossal-AI breaks the world record”, which aroused enthusiastic response. In this post, we will provide detailed annotations of the code.
Code address: https://github.com/hpcaitech/ColossalAI/tree/main/examples/vit_b16_imagenet_data_parallel
Overview
A common way to speed up AI model training is to implement large-batch training with the help of data parallelism, but this requires expensive supercomputer clusters. In this example, we used a small server with only 4 GPUs to reproduce the large-scale pre-training of Vision Transformer (ViT) on ImageNet-1K in 14 hours.
Quick Start
On a single server, you can directly use torch.distributed to start pre-training on multiple GPUs in parallel.
python -m torch.distributed.launch --nproc_per_node <num_of_gpus> train_dali.py --world_size <num_of_gpus> --config <path to your config file>
For scaling on a GPU cluster, you can use the Slurm Workload Manager to start the following commands and get running environment information.
srun python train_dali.py --local_rank=$SLURM_PROCID --world_size=$SLURM_NPROCS --host=$HOST --port=29500 --config=vit-b16.py
Experiments
To facilitate more people to reproduce the experiments with large-scale data parallel, we pre-trained ViT-Base/32 in only 14.58 hours on a small server with 4 NVIDIA A100 GPUs using ImageNet-1K dataset with batch size 32K for 300 epochs maintaining accuracy. For more complex pre-training of ViT-Base/16 and ViT-Large/32, it also takes only 78.58 hours and 37.83 hours to complete. Since the server used in this example is not a standard NVIDIA DGX A100 supercomputing unit, perhaps a better acceleration can be obtained on more professional hardware.
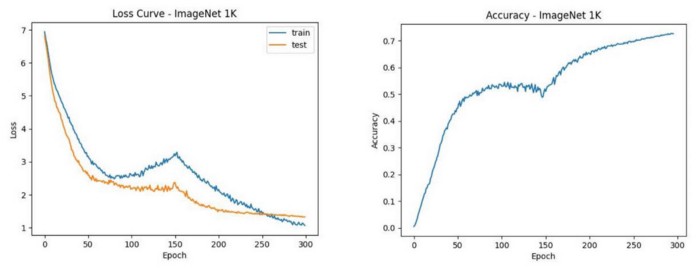
As can be seen from the above figure, the ViT model eventually converges well after training 300 epochs. It is worth noting that, unlike the common small-batch training convergence process, the model performance has a temporary decline in the middle of the large-batch training process. This is due to the difficulty of convergence in large-batch training. As the number of iterations is reduced, a larger learning rate is needed to ensure the final convergence. Since we did not carefully adjust the parameters, perhaps other parameter settings could get better convergence.
Code details
vit-b16.py
This is a configuration file that defines training parameters used by Colossal-AI, such as model, dataset, training methods (optimizer, learning rate scheduler, number of epochs, etc.). The config content can be accessed through gpc.config in the program.
In this example, we trained ViT-Base/16 for 300 epochs on the ImageNet-1K dataset. The batch size is expanded to 32K through data parallelism. Since only 4 A100 GPUs on one small server are used, and the GPU memory is limited, the batch size of 32K cannot be used directly. Therefore, the batch size used on each GPU is only 256, and the 256 batch size is equivalently expanded to 8K through gradient accumulation 32 times. Finally, data parallelism is used between 4 GPUs to achieve an equivalent batch size of 32K.
Since the batch size of 32K far exceeds the use range of common optimizers and is difficult to train, we use the large-batch optimizer LAMB provided by Colossal-AI to achieve a better convergence. The learning rate and weight decay of LAMB are set to 1.8e-2 and 0.1, respectively. The learning rate scheduler uses a linear warmup strategy of 150 epochs. We also used FP16 mixed precision to speed up the training process, and introduced gradient clipping to help convergence. For simplicity and speed, we only use Mixup instead of RandAug in data augmentation.
By tuning the parallelism, this example can be quickly deployed to a single server with several GPUs or to a large cluster with lots of nodes and GPUs. If there are enough computing resources to allow data parallel to be directly extended to hundreds or even thousands of GPUs, the training process of several days on a single A100 GPU can be shortened to less than half an hour.
imagenet_dali_dataloader.py To speed up the training process, we use NVIDIA’s DALI to read data and require the dataset to be in TFRecord format, which avoids directly reading a large number of raw image files and being limited by the efficiency of the file system.
train_dali.py We call DALI in this file to read data and start the training process using Colossal-AI.
mixup.py Since Mixup is used as data augmentation, we define the loss function of Mixup here.
hooks.py We define hook functions that record running information to help debugging.
More Features
Colossal-AI is still in the beta testing stage, and more amazing results will be released in the near future.
We will also make intensive iterative updates based on user feedback and established plans to provide users with the official version as soon as possible.
The Colossal-AI team will also release several open-source subsystems within one year, eventually forming a rich solution for high-performance AI platforms to fully meet the different needs of users.
Join Us
The core members of HPC-AI Tech team are from the University of California, Berkeley, Stanford University, Tsinghua University, Peking University, National University of Singapore, Singapore Nanyang Technological University, and other well-known universities in the world. At present, HPC-AI Tech is recruiting full-time/intern software engineers, AI engineers, SaaS engineers, architecture/compiler/network/CUDA, and other core system developers.
HPC-AI Tech provides competitive salaries. Excellent applicants can also apply for remote work. You are also welcome to recommend outstanding talents to HPC-AI Tech. If they successfully sign up for HPC-AI Tech, we will provide you with a recommendation fee of hundreds to thousands of dollars.
Resume delivery mailbox: hr@hpcaitech.com
Portal
Paper Address: https://arxiv.org/abs/2110.14883
Project Address: https://github.com/hpcaitech/ColossalAI
Document Address: https://www.colossalai.org/
Comments