
Global technology companies are scrambling to enter the AI large model competition by building models similar to ChatGPT/GPT-4. Consequently, the amount of financing, mergers, and acquisitions obtained by AIGC-related companies has reached record highs.
However, an extremely high cost accompanies the skyrocketing popularity of AI models, with a single pre-training typically requiring millions of dollars. Depending on the fine-tuning needed for existing open source models such as LLaMA, it can also be difficult to build competitiveness and diversified commercial use suitable for the expectations of enterprises. An inexpensive method to build customized pre-training bases for large models has thus become a critical bottleneck in this new age of large AI models.
Colossal-AI—the world's largest and most active big model development tool and community—utilizes the current most widely used large model, LLaMA, to provide an example of the tool’s groundbreaking pre-training solutions for the 65 billion parameter large model which improves the training speed by 38%. This can save enormous amounts for large model enterprises.
You can find the open-source code for Colossal-AI here.
LLaMA ignites open-source enthusiasm
Meta open source 7B~65B large model, LLaMA, sparked the enthusiasm for building models similar to ChatGPT and was thus derived from Alpaca, Vicuna, ColossalChat, and other fine-tuning projects.
However, only LLaMA’s model weights are open source and commercial use is restricted, so the knowledge and capabilities that fine-tuning can enhance and insert is relatively limited. For enterprises that are eager to join the wave of big models, they still must pre-train their own core big models. The open-source community has made many efforts regarding this task:
- RedPajama: open source, commercially available, LLaMA-like dataset without training code and models
- OpenLLaMA: open source, commercially available, LLaMA-like 7B/13B model, uses EasyLM based on JAX and TPU training
- Falcon: open source, commercially available, LLaMA-like 7B/40B models, no training code
Despite these efforts, there is still a lack of efficient, reliable, and easy-to-use pre-training solutions for LLaMA-like large base models in the most mainstream PyTorch + GPU ecosystems.
The top large model pre-training solution with a 38% speed-up
To address the gaps and concerns mentioned above, Colossal-AI is the first system to open-source a low-cost pre-training solution for LLaMA, which has 65 billion parameters. Colossal AI does not limit commercial use and only needs 32 A100/A800 GPUs to improve pre-training speed by 38% compared to other mainstream options in the industry.
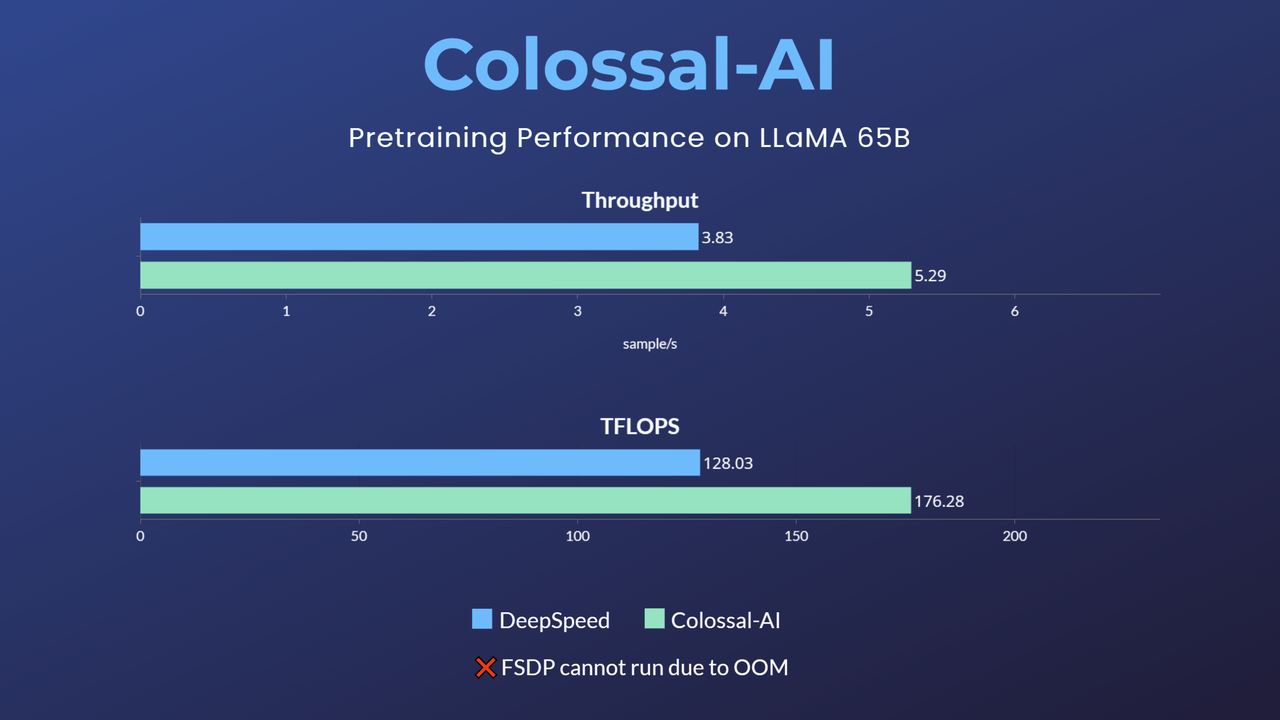
While, like PyTorch, FSDP, etc., the task cannot be run due to being out of GPU memory. Hugging Face Accelerate, DeepSpeed, and Megatron-LM also do not have official support for LLaMA pre-training.
Quick Start
- Install Colossal-AI
| git clone -b example/llama https://github.com/hpcaitech/ColossalAI.git cd ColossalAI # install and enable CUDA kernel fusion CUDA_EXT=1 pip install . |
2. Install other dependencies
| cd examples/language/llama # install other dependencies pip install -r requirements.txt # use flash attention pip install xformers |
3. Dataset
The default dataset (togethercomputer/RedPajama-Data-1T-Sample) will be downloaded automatically on the first run, or you can specify a custom dataset via -d or --dataset.
4. Run CommandThe 7B and 65B benchmark scripts have been provided. You only need to set the hostname of the multi-node usage according to the actual hardware environment you will run.
| cd benchmark_65B/gemini_auto bash batch12_seq2048_flash_attn.sh |
For actual pretraining tasks, use the same command as the speed benchmark, such as using 4 nodes * 8 cards to train the 65B model.
| colossalai run --nproc_per_node 8 --hostfile YOUR_HOST_FILE --master_addr YOUR_MASTER_ADDR pretrain.py -c '65b' --plugin "gemini" -l 2048 -g -b 8 -a |
For example, using the Colossal-AI gemini_auto parallelism strategy, it is convenient to achieve high-speed multi-node and multi-GPU parallel training, while reducing the consumption of GPU memory. You can also choose a combination of complex parallelism strategies such as pipeline parallelism + tensor parallelism + ZeRO1 data parallelism, according to the hardware environment or your needs.
Users can conveniently control dozens of command line arguments, maintaining high speed while keeping flexibility for custom development. In particular, Colossal-AI's Booster Plugins allow users to easily customize parallel training, such as choosing Low-Level ZeRO, Gemini, DDP, etc. Gradient checkpointing reduces memory usage by recalculating the model's activation during backpropagation. Flash attention is introduced to speed up computation and save GPU memory.
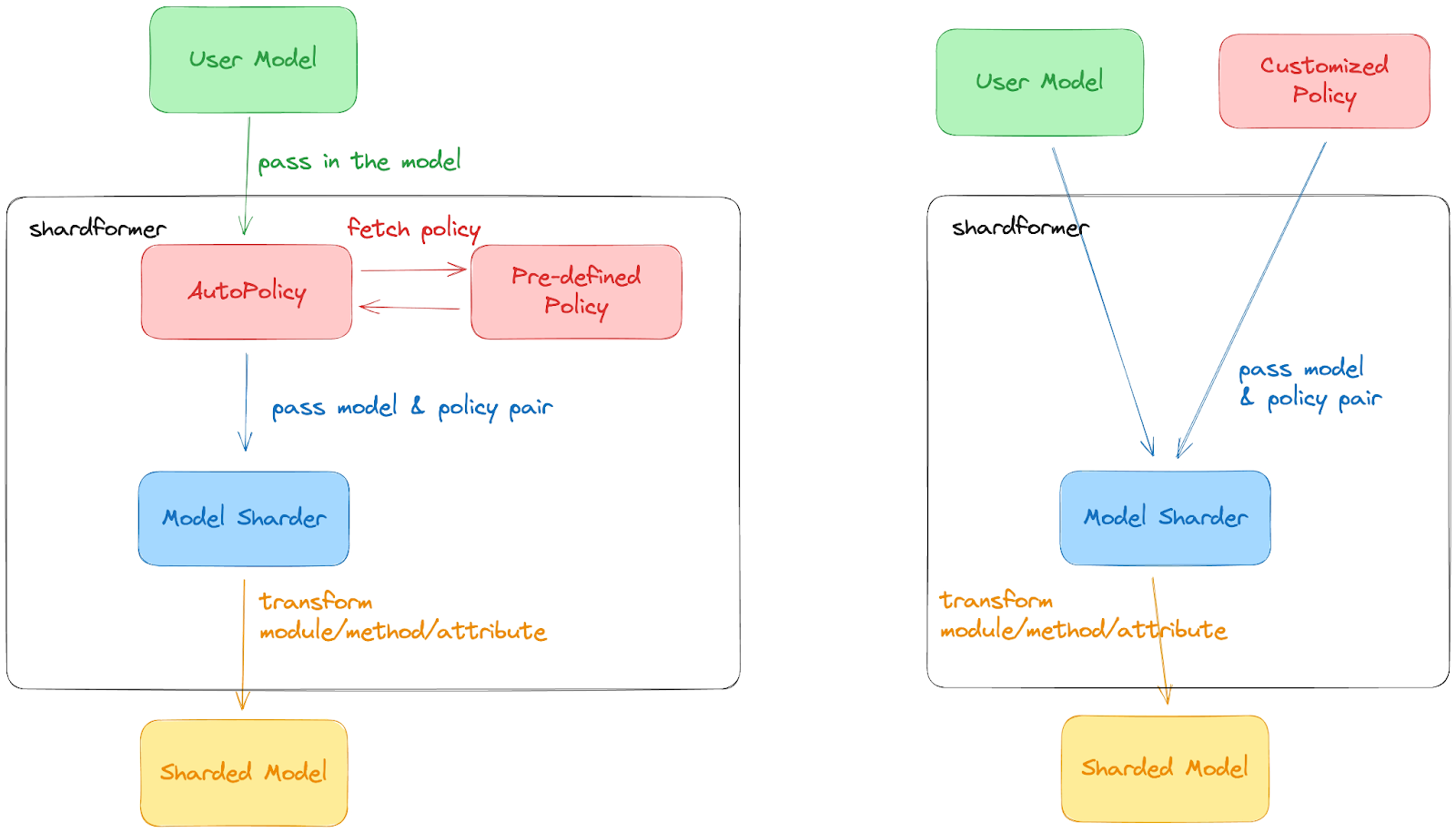
Colossal-AI's latest Shardformer dramatically reduces the cost of getting started with multidimensional parallel training of LLMs. It now supports a wide range of mainstream models, including LLaMA, and natively supports the Huggingface/transformers model library. Without the need to modify the model, it can support various parallelism (pipeline, tensor, ZeRO, DDP, etc.), and can achieve excellent performance in various hardware configurations.
Colossal-AI: Making large AI models cheaper, faster, and more accessible
The core system optimization and acceleration capabilities for this solution are made possible by Colossal-AI, which was developed based on the expertise of Prof. James Demmel, a Distinguished Professor at UC Berkeley, and Prof. You Yang, a Presidential Young Professor at the National University of Singapore. Colossal-AI is based on PyTorch, which reduces both large AI model training/fine-tuning/inference costs and GPU requirements through efficient multidimensional parallelism, heterogeneous memory, etc.
Since its open-source release, Colossal-AI has ranked first on GitHub Trending multiple times with more than 30,000 GitHub Stars. It has been accepted as the official tutorial for numerous international AI and HPC top conferences including SC, AAAI, PPoPP, CVPR, and ISC. Over a hundred companies have participated in building the Colossal-AI ecosystem.
HPC-AI Tech, the company behind Colossal-AI, has recently obtained tens of millions of dollars in Series A financing and has completed three rounds of financing within 18 months of its establishment.
The open-source code of Colossal-AI is available here.
![]()
Reference
- https://github.com/openlm-research/open_llama
- https://github.com/togethercomputer/RedPajama-Data
- https://huggingface.co/tiiuae
Comments