
Not long ago OpenAI Sora quickly became popular with its amazing video generation effect, standing out among a bunch of Text-to-Video models and becoming the focus of global attention. Following the launch of the Sora Replication for both training and inference process with 46% cost reduction 2 weeks ago, the Colossal-AI team has a new open source solution, "Open-Sora 1.0", which covers the entire training process, including data processing, all training details and model checkpoints, to join hands with AI enthusiasts around the world to advance a new era of video creation.
Let's take a first look at a video of a bustling urban night scene generated by the "Open-Sora 1.0" model released by the Colossal-AI team.

Open-Sora 1.0 generated cityscapes
This is just the tip of the iceberg of Open-Sora technology. Colossal-AI team has fully open-sourced the model architecture, trained model checkpoints, details of all the training and data preparation processes, video demos and tutorials in our GitHub for everyone interested in Text-to-Video models to freely learn and use. We will continue to update Open-Sora related solutions and the latest developments. We will be consistently updating Open-Sora solutions and the latest news in this GitHub repo and welcome everyone to stay tuned for updates!
-
Open-Sora open source address: https://github.com/hpcaitech/Open-Sora
Comprehensive Explanation of Open Sora
Next, we will provide an in-depth explanation of multiple key dimensions of the Sora reproduction scheme, including model architecture design, training reproduction scheme, data preprocessing, model output demonstration, and efficient training optimization strategies.
Model Architecture Design
Our model utilizes the currently popular Diffusion Transformer (DiT) [1] architecture. We use PixArt-α [2], a high-quality open-source text-to-image model that also uses the DiT architecture as a base, and extend it to generate video by adding a temporal attention layer. Specifically, the entire architecture consists of a pre-trained VAE, a text encoder, and an STDiT (Spatial Temporal Diffusion Transformer) model that utilizes the spatial-temporal attention mechanism. The structure of each layer of STDiT is shown below. It uses a serial approach to superimpose a 1D temporal attention module on a 2D spatial attention module for modelling temporal relationships. After the temporal attention module, the cross-attention module is used to align the semantics of the text. Compared to the full-attention mechanism, such a structure greatly reduces training and inference costs. Compared to the Latte [3] model, which also uses a spatial-temporal attention mechanism, STDiT can better utilize the weights of the pre-trained image DiTs to continue training on video data.
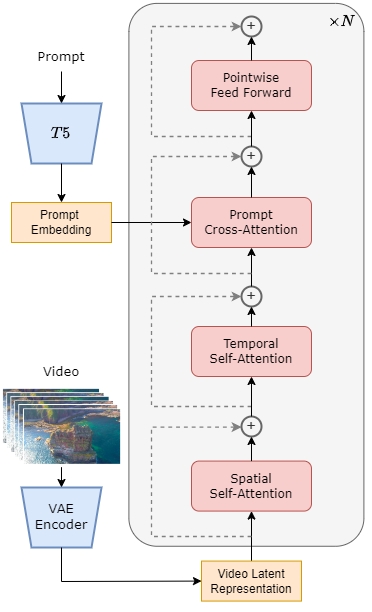
STDiT Model Structure Schematic
The training and inference process of the whole model is as follows. In the training stage, we first use a pre-trained VAE(Variational Autoencoder) encoder to compress the video data, and then train our proposed STDiT model with text embedding in the latent space after compression. In the inference stage, we randomly sample a Gaussian noise from the latent space of the VAE and input it into the STDiT together with the prompt embedding to get the features after denoising, and finally input it into the VAE decoder to get the video.

Model Training Process
Training Reproduction Scheme
Open-Sora's reproduction scheme references the Stable Video Diffusion (SVD) [3] work and consists of three phases, namely:
Each stage continues training based on the weights of the previous stage. Compared to single-stage training from scratch, multi-stage training achieves the goal of high-quality video generation more efficiently by gradually expanding the data.
%20(5).gif?width=1600&height=400&name=High-performance%20and%20low-cost%20implementations%20Validated%20performance%2c%20easy-to-use%20solutions%20Technical%20support%20and%20expertized%20assistance%20(1600%20x%20900%20%E5%83%8F%E7%B4%A0)%20(5).gif)
-
First Stage: Large-scale image pre-training
The first stage effectively reduces the cost of video pre-training through large-scale image pre-training with the help of a mature Text-to-Image model.
With the abundant large-scale image data on the Internet and advanced Text-to-Image technology, we can train a high-quality Text-to-Image model, which will be used as the initialization weights for the next stage of video pre-training. Meanwhile, since there is no high-quality spatio-temporal VAE, we utilize the Stable Diffusion [5] model to pre-train the spatial VAE. This strategy not only guarantees the superior performance of the initial model but also significantly reduces the overall cost of video pre-training.
-
Second Stage: Large-scale video pre-training
The second phase performs large-scale video pre-training to increase the model's generalization ability and effectively grasp the time series association of videos.
This phase requires the use of a large amount of video data training to ensure the diversity of video topics, thus increasing the generalization ability of the model. The model in the second stage adds a temporal sequence attention module to the first stage Test-to-Image model for learning the temporal relationships in videos. The rest of the modules are kept the same as the first stage and loaded with the first stage weights as initialization while initializing the output of the temporal attention module to zero for more efficient and faster convergence. We used the open source weights of PixArt-α [2] as initialization for the second stage STDiT model, as well as adopted the T5 [6] model as the text encoder. Meanwhile, we used a small resolution of 256x256 for pre-training, which further increases convergence speed and reduces the training cost.
-
Third Stage: High-quality video data fine-tuning
The third phase fine-tunes the high-quality video data to significantly improve the quality of the video generated.
The size of the video data used in the third phase is an order of magnitude less than in the second phase, but the video is of higher duration, resolution, and quality. By fine-tuning in this way, we achieve efficient scaling of video generation from short to long, from low to high resolution, and from low to high fidelity.
In our reproduction process, we used 64 H800 GPUs for training. The training volume for the second phase totalled 2,808 GPU hours, which is about $7,000, and the training volume for the third phase was 1,920 GPU hours, which is about $4,500, and we successfully kept the Open-Sora reproduction process at about $10,000 USD.
Data Preprocessing
To further reduce the barrier and complexity of Sora replication, the Colossal-AI team also provides convenient video data preprocessing scripts in the code repository, including public video dataset download, long video segmentation into short video clips based on shot continuity, and using the open source big language model LLaVA [7] to generate fine-grained cue words, so that you can easily start Sora replication pre-training. The batch video caption generation code we provide can annotate a video using two GPUs in 3 seconds and the quality is close to GPT-4V. The final video-text pairs can be directly used for training. With the code we provide, users can easily and quickly generate the video-text pairs required for training on their own datasets, significantly reducing the technical barrier and prep for starting a Sora replication project.

Automatically generated video/text pairs based on data preprocessing scripts
Video Demos
Let's take a look at Open-Sora's actual video generation results. For example, let's let Open-Sora generate an aerial footage of the sea lapping against the rocks by the cliff coast.

Then let our Open-Sora capture the magnificent bird's eye view of a mountain waterfall surging down a cliff and eventually merging into a lake.

In addition to the sky, we can also generate videos about the sea. With a simple input prompt, we let Open-Sore generate a video about a sea turtle in the coral reefs swimming leisurely.

Open-Sora is also able to show us the Milky Way in all its starry splendor through time-lapse photography.

If you have more interesting ideas for video generation, welcome to our Open-Sora open-source community to get model weights for free experience.
Link: https://github.com/hpcaitech/Open-Sora
It is worth noting that our current version only uses 400K of training data, and the model's generation quality and ability of text following could be improved. For example, in the turtle video above, the generated turtle has an extra foot. Open-Sora 1.0 is also not very good at generating portraits and complex images. We have a list of plans on GitHub and will continue to address the existing bugs and improve the quality of the generation.
Efficient Training
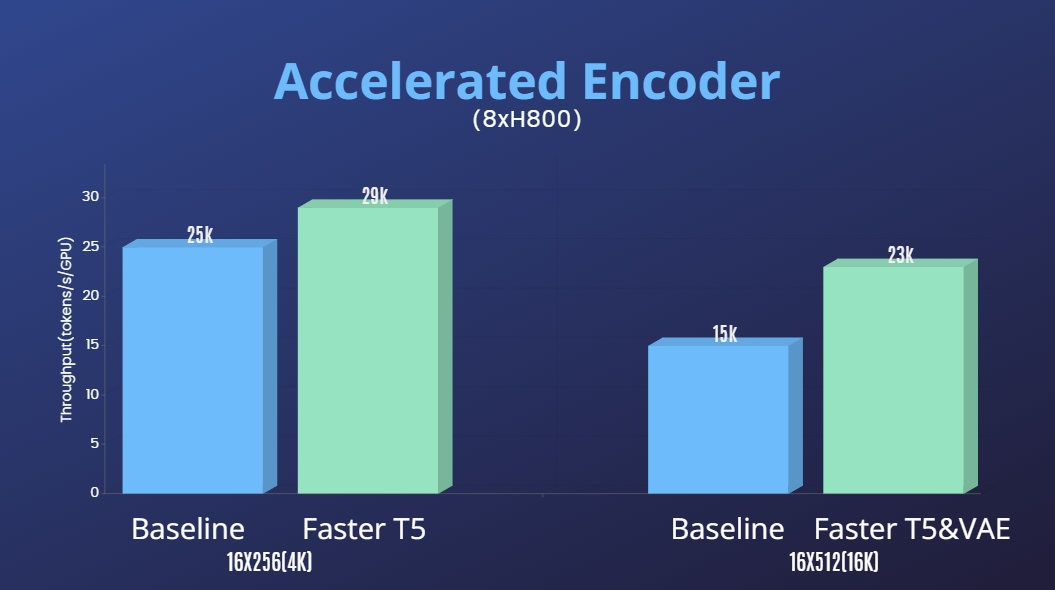
In addition to significantly lowering the technical threshold of Sora reproduction and improving the quality of video generation in multiple dimensions such as duration, resolution, and content, we also provide Colossal-AI acceleration system for efficient training. Through efficient training strategies such as kernel optimization and hybrid parallelism, we achieve 1.55x acceleration in training for processing 64-frame, 512x512 resolution videos. Meanwhile, thanks to Colossal-AI's heterogeneous memory management system, we can perform a 1-minute 1080p HD video training task on a single server (8*H800) without any hindrance.
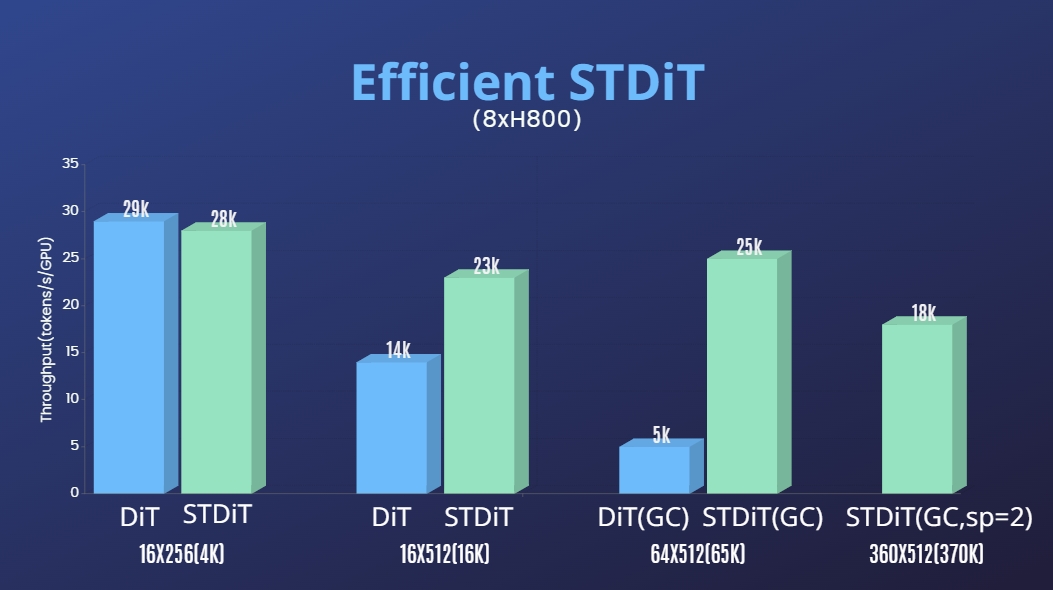
In addition, our proposed STDiT model architecture demonstrates superior efficiency during training. Compared to DiT with a full-attention mechanism, STDiT achieves up to 5x speedup as the number of frames increases, which is especially critical in real-world tasks such as processing long video sequences.
Open-Sora video at a glance
Welcome to keep following the Open-Sora open-source project: https://github.com/hpcaitech/Open-Sora
Subsequently, we will continue to maintain and optimize the Open-Sora project by utilizing more video training data to generate higher quality and longer video content and supporting multi-resolution features to effectively promote AI technology in the fields of film, games, advertising and other areas of landing.
Reference
[1] https://arxiv.org/abs/2212.09748 Scalable Diffusion Models with Transformers
[2] https://arxiv.org/abs/2310.00426 PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
[3] https://arxiv.org/abs/2311.15127 Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
[4] https://arxiv.org/abs/2401.03048 Latte: Latent Diffusion Transformer for Video Generation
[5] https://huggingface.co/stabilityai/sd-vae-ft-mse-original
[6] https://github.com/google-research/text-to-text-transfer-transformer
[7] https://github.com/haotian-liu/LLaVA
Comments