
The development of artificial intelligence(AI) and high-performance computing(HPC) has dramatically revolutionized our lives and brought significant potential to our society. For example, Facebook has 1.82 billion daily active users and issues tens of trillions of inference queries per day, which requires essential changes in the development process and system design.
Traditional deep learning(DL) systems usually focus on the single-model single-machine inference setting. However, the exponential growth of DL models leads to an inability to execute large pre-trained models on a single machine. Specifically, super large NLP models like GPT-3 require more than one hundred GBs of memory for inference. One single GPU is not enough to hold such tasks, which makes using multiple distributed computing devices to inference collaboratively the future of large model inference.
The Colossal-AI team developed Energon-AI, as a subsystem, to provide inference service for super-scale DL models. Focusing on the specific pain points, Colossal-AI Team delved into multi-device inference situations, developed large scale inference system Energon-AI, with their idea of “High Performance, High Usability, High Versatility”.
With few changes to existing projects, users could easily develop large models for inference, achieve superlinear speedups on parallel extensions. Compared to FastTransformer introduced by NVIDIA, Energon-AI managed to reach an improvement of 50% on parallelized inference speedups with large AI models.
Besides, different from current inference solutions, Energon-AI does not require manual settings for communication or memory usage, neither does extra compiling. By using Energon-AI, inference becomes way easier than before.
Open source address: https://github.com/hpcaitech/ColossalAI
Difficulties with Large AI Model Inference
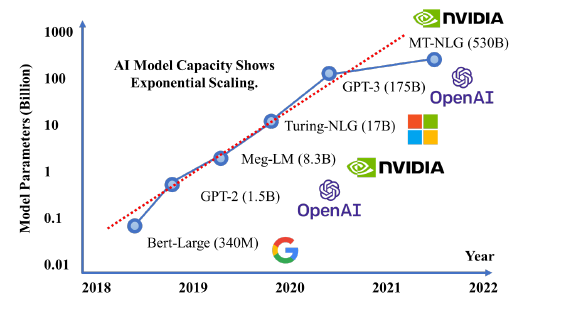
Recently, computing devices such as GPUs have been greatly upgraded focusing on their parallel computing capability, memory capacity, memory speed, etc. However, such performance improvements on a single device could never meet the requirements of large models whose parameter size grows exponentially. Current deep learning inference systems mainly focus on simple scenarios like multi-model single-machine and single-model single-machine, overlooking the challenges and opportunities of single-model multi-machine scenarios that are essential for large AI model inference. Thus, we introduced Energon-AI system to solve these severe issues.
Large Scale Inference System: Energon- AI
System Design
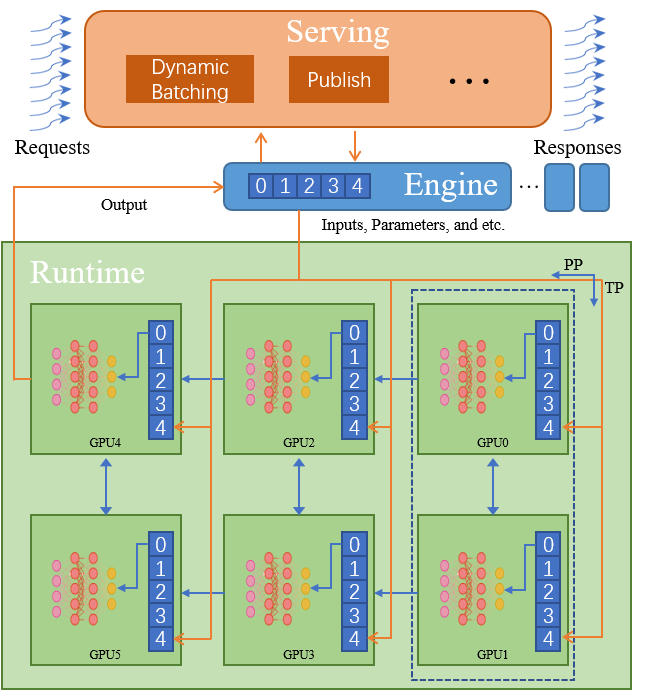
Focusing on the deployment of large AI models, we design a single-model multi-machine inference system, Energon-AI. Its system is comprised of three levels, namely runtime system (Runtime), distributed inference instance (Engine) and service system (Serving):
-
Runtime: In the design of the runtime system, we find that with tremendous model scaling, the time taken by general matrix multiplications gradually increases. Conversely, the time taken by memory-intensive operators and Kernel Launch shows a decreasing pattern. The process is further migrated from memory-intensive to computing-intensive, and the effect of TensorRT and specified inference systems for memory-intensive operations is greatly reduced. Energon-AI Runtime relies on Colossal-AI to achieve tensor parallelism. Meanwhile, we also design a pipeline parallel packaging method for insufficient memory. In addition, we introduce a large number of special inference operators and methods. For example, when it comes to the variable length of input in NLP, we introduce operators such as transpose_padding_rebulid and transpose_padding_remove to efficiently process MLP layers in the Encoder and Decoder models.
-
Engine: To make Engine have exactly the same behavior as single-device inference through encapsulation, we adapt a semi-centralized method and use RPC to call initialization or inference methods on each device in the main process, so that distributed inference can be centrally controlled. Meanwhile, each device maintains its own communication logic for Tensor Parallel and Pipeline Parallel. We design and maintain a distributed message queue in each process to ensure the consistency of multi-threaded call execution in multiple processes.
-
Serving: Energon-AI introduces a dynamic batching mechanism. After the requests in the request queue are optimally packaged according to machine performance, Energon-AI selects the batch processing with the highest priority regarding the waiting time, batch size, batch expansion possibility (based on the sentence length after padding), etc., which enables the maximization of the GPU usage while avoiding the starvation problem and reducing the average request delay.
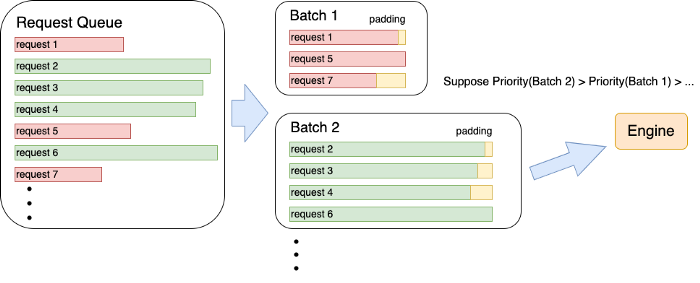
Performance Testing
Superlinear Scaling of Parallel Inference
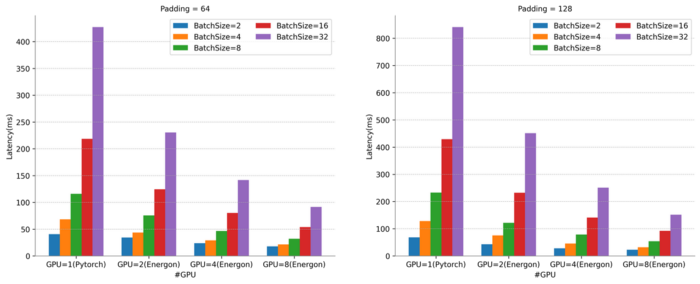
When the Batch Size is 32, Energon-AI parallel inference with 8 GPUs can achieve an 8.5-time super-linear speedup compared to Pytorch direct inference with one GPU.
Runtime Inference Performance Improved by 50%
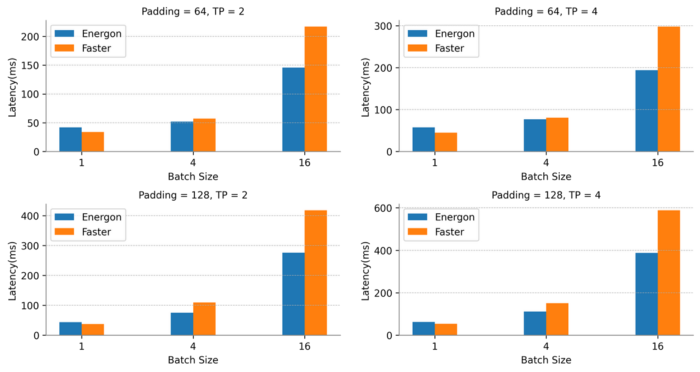
We compare our Energon-AI with highly optimized FasterTransformer GPT-3 introduced by NVIDIA. Faster Transformer introduces its distributed inference feature in its 4.0 version, and currently supports distributed inference of the GPT-3 model. However, due to its highly coupled pure C++ code, its flexibility and usability are relatively low. In addition, regarding the characteristics of different lengths of input sentences for NLP inference, its distributed inference has no redundant computation elimination method.
For the GPT-3 model, the runtime system of Energon-AI performs slightly lower than FasterTransformer when the batch size is 1, while it could achieve more than 50% performance improvement when the batch size increases.
30% Increase in Dynamic Batching Throughput
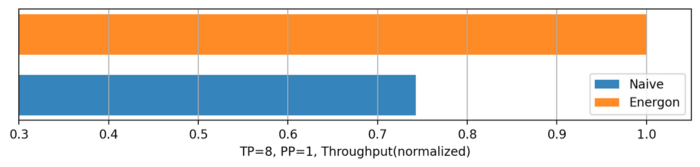
We simulate a real-world scenario where multiple users send a large number of vary-length inference requests at the same time, and compare the throughput of our dynamic batch method with the traditional FIFO (first-in-first-out) method. Since the dynamic batching algorithm alleviates the problem of massive redundant computation caused by direct padding, the throughput of dynamic batching is improved by 34.7%.
High Usability
from gpt import gpt3
from gpt_batch_server import launch_engine
# for engine
model_class = gpt3
model_type = "gpt"
host = "127.0.0.1"
port = 29401
half = True
backend = "nccl"
# for parallel
tp_init_size = 4
pp_init_size = 2
# for server
engine_server = launch_engine
server_host = "127.0.0.1"
server_port = 8020
rm_padding = False
energonai service init --config_file=gpt_config.py
While pursuing high performance, Energon-AI hopes to maintain high flexibility and usability of the system. Users only need to customize [parallel model], [parallel parameters] and [service request logic] in the configuration file to start an inference task. Currently, we provide the most common GPT, BERT and ViT models as examples, and more detailed tutorials will be provided in the near future.
When building a new parallel model, Energon-AI uses Python, and the usage is similar to Pytorch. It has the concept of layers and its logic of initialization and execution is clear. Users do not need to consider memory management or parallel communication. The following codes show how to run a model with two Linear layers in parallel with Energon-AI.
class MLP(nn.Module):
def __init__(self, dim, dtype, bias):
super().__init__()
self.dense_0 = Linear1D_Col(dim, dim, dtype=dtype, bias=bias, gather_output=False)
self.dense_1 = Linear1D_Row(dim, dim, dtype=dtype, bias=bias, parallel_input=True)
def forward(self, x):
x = self.dense_0(x)
x = self.dense_1(x)
return xIn contrast, when using FasterTransformer to build a new parallel model, users are required to write in C++ and manually set underlying behavior organizations such as managing memory, defining communication, etc. Due to space limitations, the following code shows the part needed for memory management, and communication settings of a two Linear layer model running in parallel with FasterTransformer. Besides, users need to spend a lot of time and energy to debug if they want the code to execute correctly, and C++ code needs additional compilation works. These all pose serious challenges to the user’s parallel knowledge and programming ability.
// Memory Allocation (only for a single paramerter).
T *d_inter_kernel = NULL
param_.ffn.intermediate_weight.kernel = d_inter_kernel;
device_malloc(&d_inter_kernel, dim * dim);
// Two MLP Layers
cublasMM_cublasLtMM_wrapper(param_.cublaslt_handle, param_.cublas_handle, CUBLAS_OP_N, CUBLAS_OP_N, n, m, k, &alpha, param_.ffn.intermediate_weight.kernel, AType_, n, attr_matmul_buf_, BType_, k, &beta, (DataType_ *)inter_matmul_buf_, CType_, n, param_.stream, cublasAlgoMap_, sm_, cublas_workspace_);
add_bias_act_kernelLauncher<DataType_>(inter_matmul_buf_, param_.ffn.intermediate_weight.bias, m, n, ActivationType::GELU, param_.stream);
n = k;
cublasMM_cublasLtMM_wrapper(param_.cublaslt_handle, param_.cublas_handle, CUBLAS_OP_N, CUBLAS_OP_N, n, m, k, &alpha, param_.ffn.output_weight.kernel, AType_, n, inter_matmul_buf_, BType_, k, &beta, (DataType_ *)(param_.transformer_out), CType_, n, param_.stream, cublasAlgoMap_, sm_, cublas_workspace_);
add_bias_input_layernorm_kernelLauncher<DataType_>(param_.transformer_out, attr_matmul_buf_, param_.ffn.output_weight.bias, param_.ffn_layernorm.gamma, param_.ffn_layernorm.beta, m, n, param_.stream);
// Communication
if(t_parallel_param_.world_size > 1)
{
all2all_gather(nccl_logits_buf_, nccl_logits_buf_, local_batch * n, t_parallel_param_, decoding_params.stream);
}More Features
The Energon-AI subsystem we released recently is beta version. Based on user feedback and plans on schedule, intensive iterative updates will be carried out gradually, and the official version will be provided to users as soon as possible to fully meet the different inference deployment needs. Your requirements and suggestions for Energon-AI are always welcomed here.
Building a Large AI Model Ecosystem
Living in an age of large AI models, in order to solve the pain points of the existing solutions such as limited parallel dimension, low efficiency, poor versatility, difficult deployment, and lack of maintenance, Colossal-AI uses technologies such as efficient multi-dimensional parallelism and heterogeneous parallelism to allow users to deploy large AI models efficiently and quickly with only a few modifications of their codes.
For example, for a super-large AI model such as GPT-3, compared to the NVIDIA solution, Colossal-AI only needs half the computing resources; if the same computing resources are used, the speed could be further increased by 11%, which could reduce the training cost of GPT-3 over a million dollars.

For AlphaFold, which is used for protein structure prediction, our team has introduced FastFold based on the Colossal-AI acceleration scheme. FastFold successfully surpassed other schemes proposed by Google and Columbia University, reducing the training time of AlphaFold from 11 days to 67 hours, and the total cost is lowered as well. Also, in long sequence inference, we achieved a speed improvement of 9.3 ~ 11.6 times.
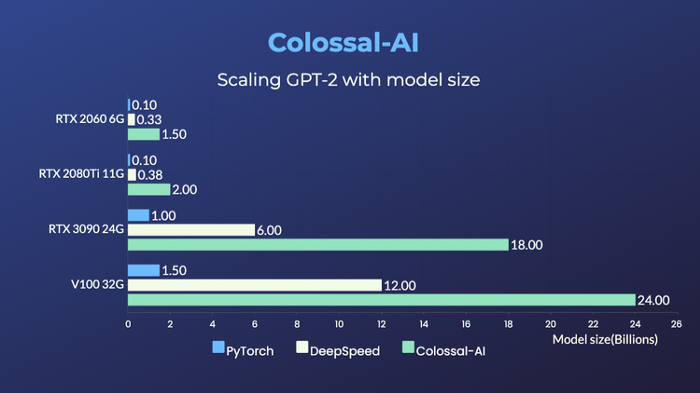
Colossal-AI is compatible with low-end devices and can train GPT with up to 18 billion parameters on a PC with only one GPU; ordinary laptops can also train models with more than one billion parameters. Compared with current popular solutions, the parameter capacity can be increased by more than 10 times, which greatly reduces the threshold for downstream tasks and application deployment such as the fine-tuning and inference of AI large model.
Besides, Colossal-AI values open source community construction, providing English and Chinese tutorials, and supporting the latest cutting-edge applications such as PaLM and AlphaFold. Colossal-AI will roll out new and innovative features regularly as well. We always welcome suggestions and discussions from the community, and we would be more than willing to help you if you encounter any issues.
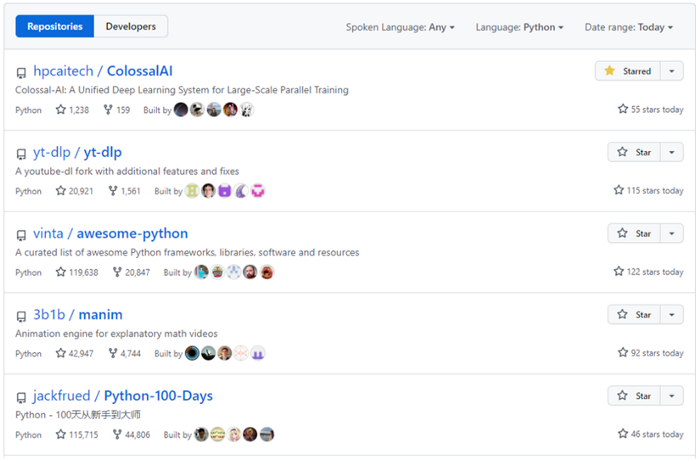
Recently, Colossal-AI reached N.01 on the top trending projects on Github, against a backdrop of many projects that have as many as 10K stars.
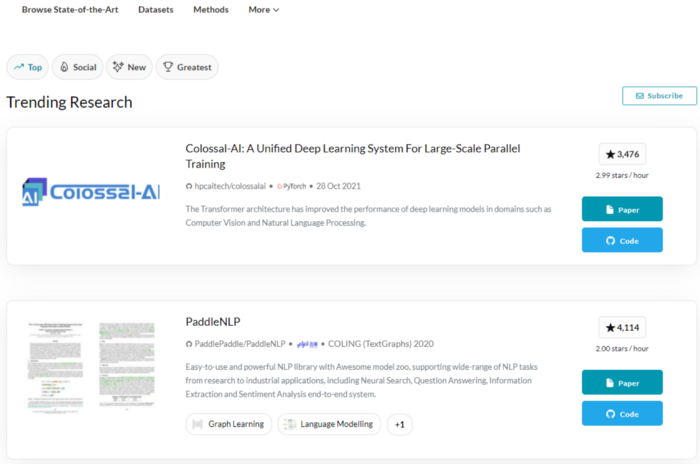
On the Papers With Code, a website which highlights trending Machine Learning research, Colossal-AI has also topped the trending list and attracted many researchers’ attention with its amazing features.
Portal
Project address: https://github.com/hpcaitech/ColossalAI
Funding
HPC-AI Tech raised 4.7 million USD from top VC firms in just 3 months after the company was founded. For more information, please email contact@hpcaitech.com.
Reference:
https://arxiv.org/pdf/2111.14247.pdf
https://www.sciencedirect.com/science/article/abs/pii/S0950584920301373
Comments