Llama 4 Online Serving
This tutorial will guide you through the process of running vllm inference solution on a trained Llama-4-Scout model.
1. Create an Instance with CUDA 12.4 Image
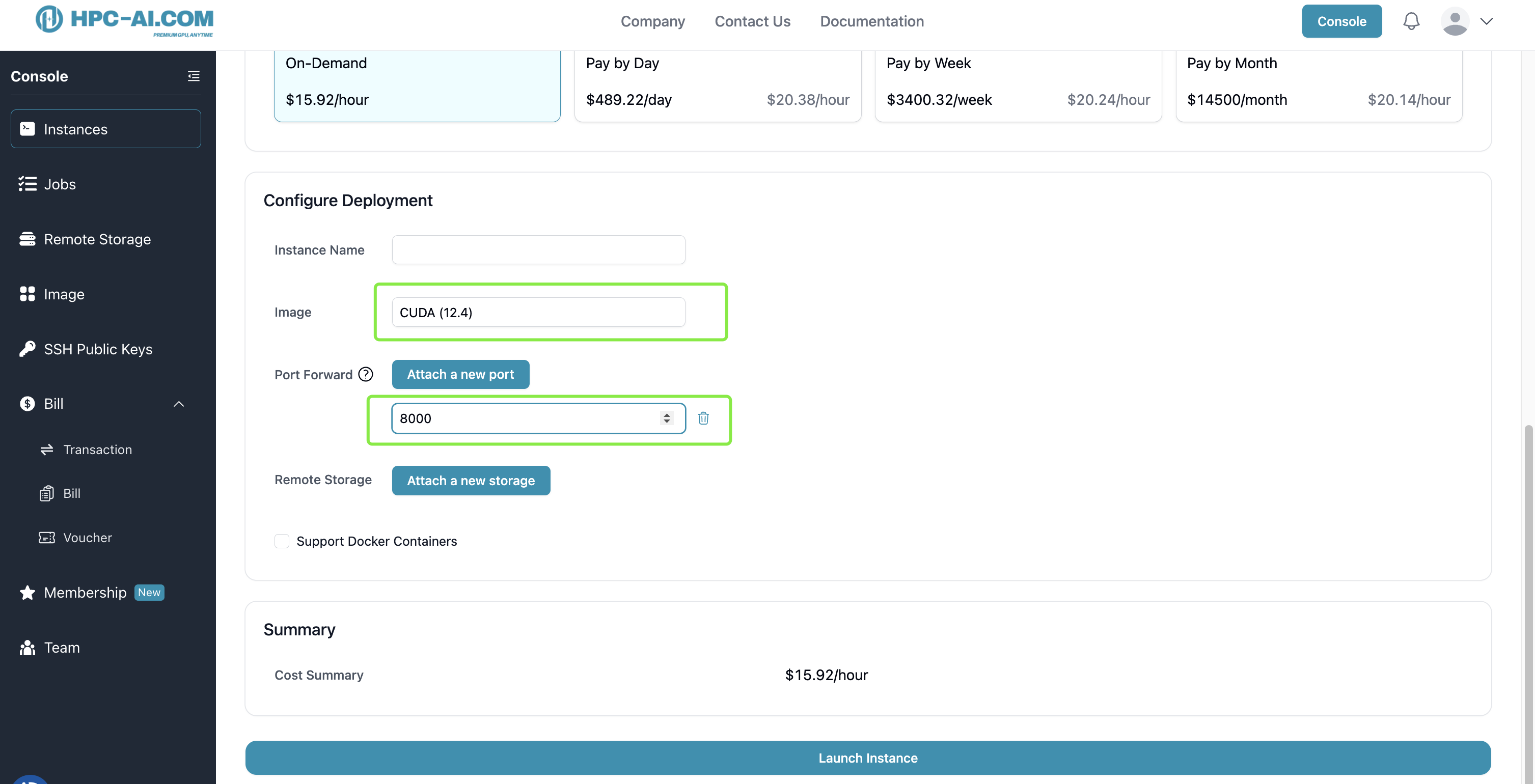
To get started with Llama 4 on HPC-AI.com, follow the instructions here to create a new instance (H200 x 8 or H100 x 8) with the CUDA 12.4 image.
Note: If you want to deploy a vllm online serving service, make sure to attend a new port of 8000 to your instance.
2. Start vllm Inference Server
Once the instance is running, click on the Jupyter Notebook link to access the Jupyter Notebook interface.
Open a terminal in the Jupyter Notebook interface to launch inference.
- Download llama-4 model from s3 storage service in our cluster
# install s3 client
wget https://dl.min.io/client/mc/release/linux-amd64/mc --no-check-certificate && chmod +x mc && mv mc /usr/bin/mc
mc alias set s3 http://seaweedfs-s3.seaweedfs:8333 readuser hpcai2025 --api s3v4
# download llama4 model from s3 to local disk
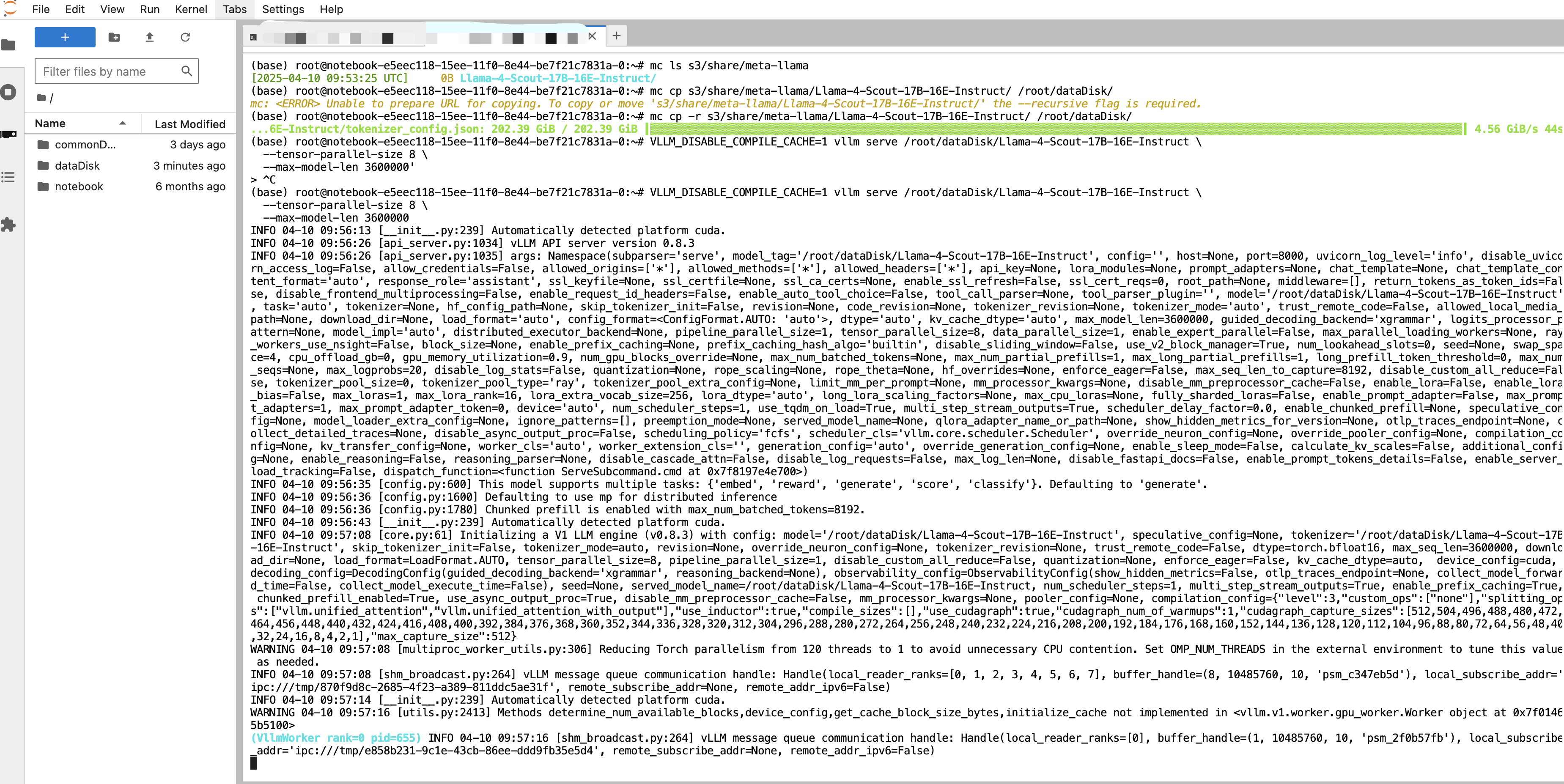
mc cp -r s3/share/meta-llama/Llama-4-Scout-17B-16E-Instruct/ /root/dataDisk/
- Install vllm and other dependencies
pip install vllm
- Run the following command to start the vllm inference server For H200 GPU x 8 (up to 3.6M context), the command is as follows:
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve /root/dataDisk/Llama-4-Scout-17B-16E-Instruct \
--tensor-parallel-size 8 \
--max-model-len 3600000
For H100 GPU x 8 (up to 1M context), the command is as follows:
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve /root/dataDisk/Llama-4-Scout-17B-16E-Instruct \
--tensor-parallel-size 8 \
--max-model-len 1000000 --override-generation-config='{"attn_temperature_tuning": true}'
It will take a while to load the model, please be patient.
3. Inference
After the model is loaded, you can start making inference requests.
Access inference endpoint locally
apt update
apt install -y curl
Open a new terminal in the Jupyter Notebook interface and run the following command to make an inference request.
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/root/dataDisk/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "who are you?"}
]
}'
Access inference endpoint outside the cluster
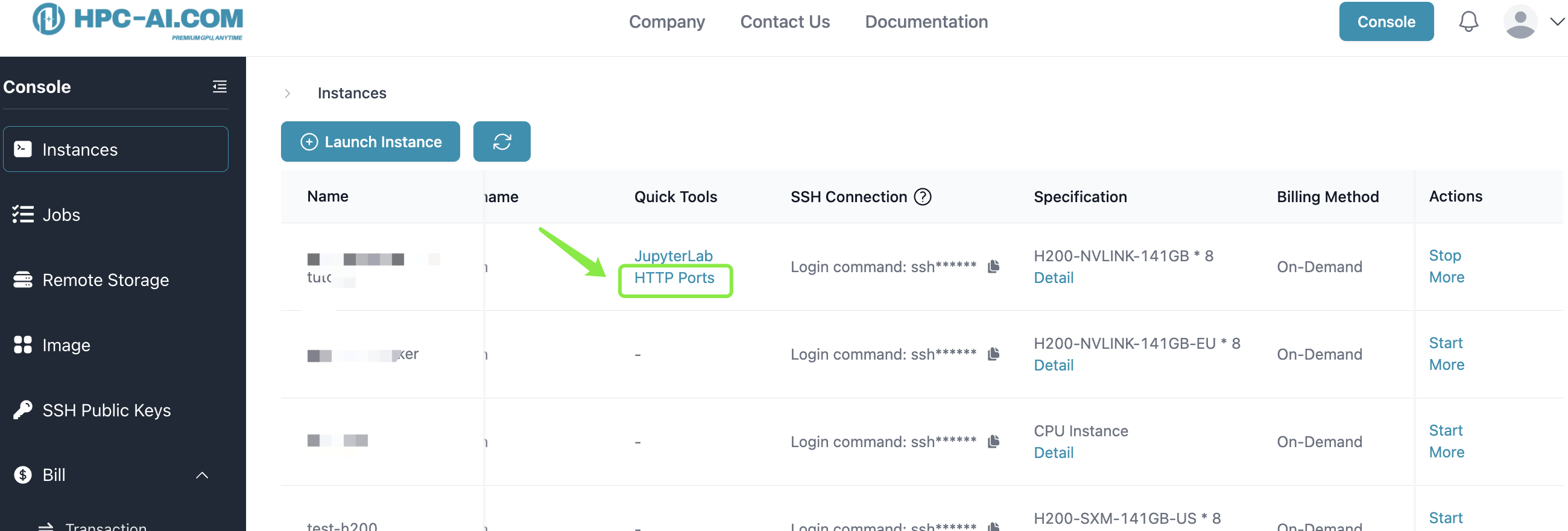
You can also access the inference endpoint outside this cluster by replacing localhost with the address public port open in this instance. You can find the port address in Quick Tools -> Http Ports.
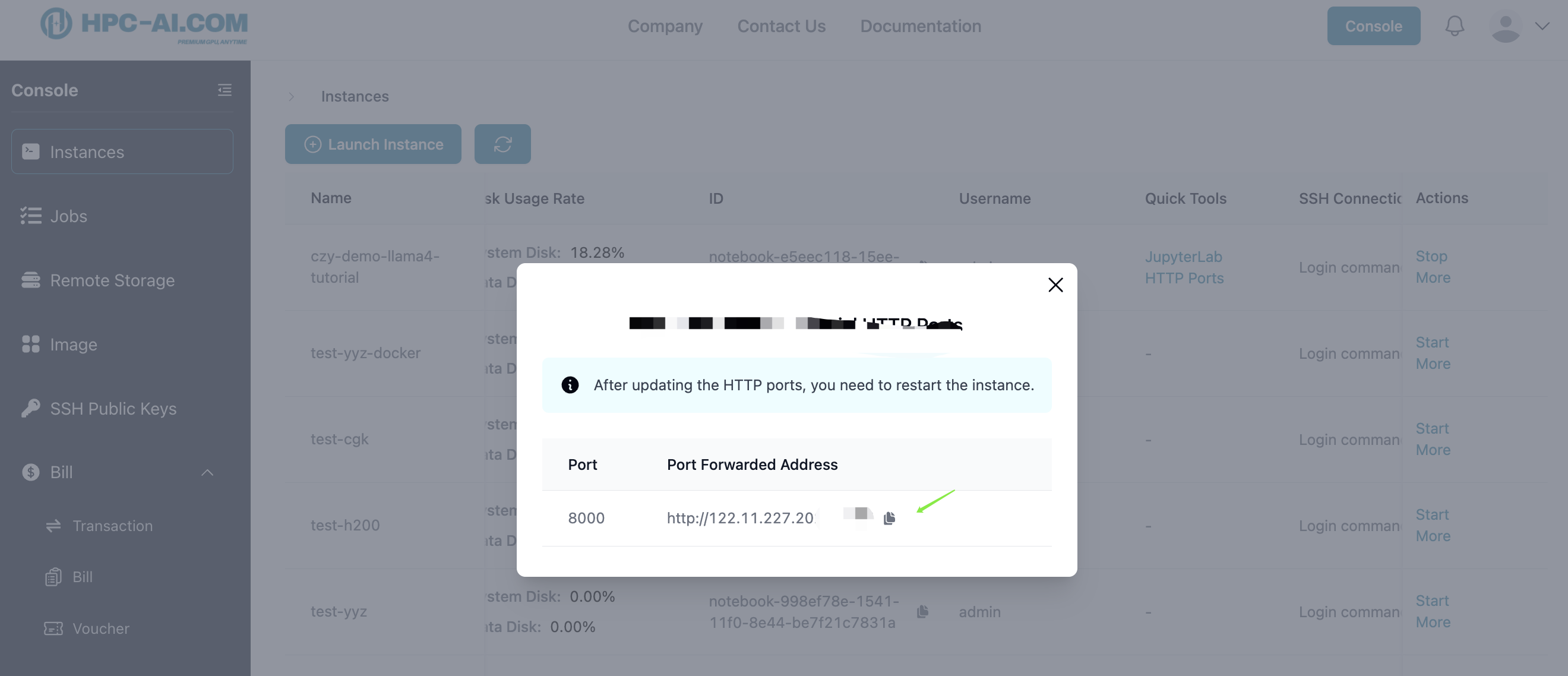
curl http://[ip:port]/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/root/dataDisk/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "who are you?"}
]
}'
Chat with inference endpoint in Cherry Studio
In cherry studio setting, add a new model provider with the following configuration:
- API Host: http://[ip:port] (You can find the port address in Quick Tools -> Http Ports.)
- API Key: empty
- Model: /root/dataDisk/Llama-4-Scout-17B-16E-Instruct
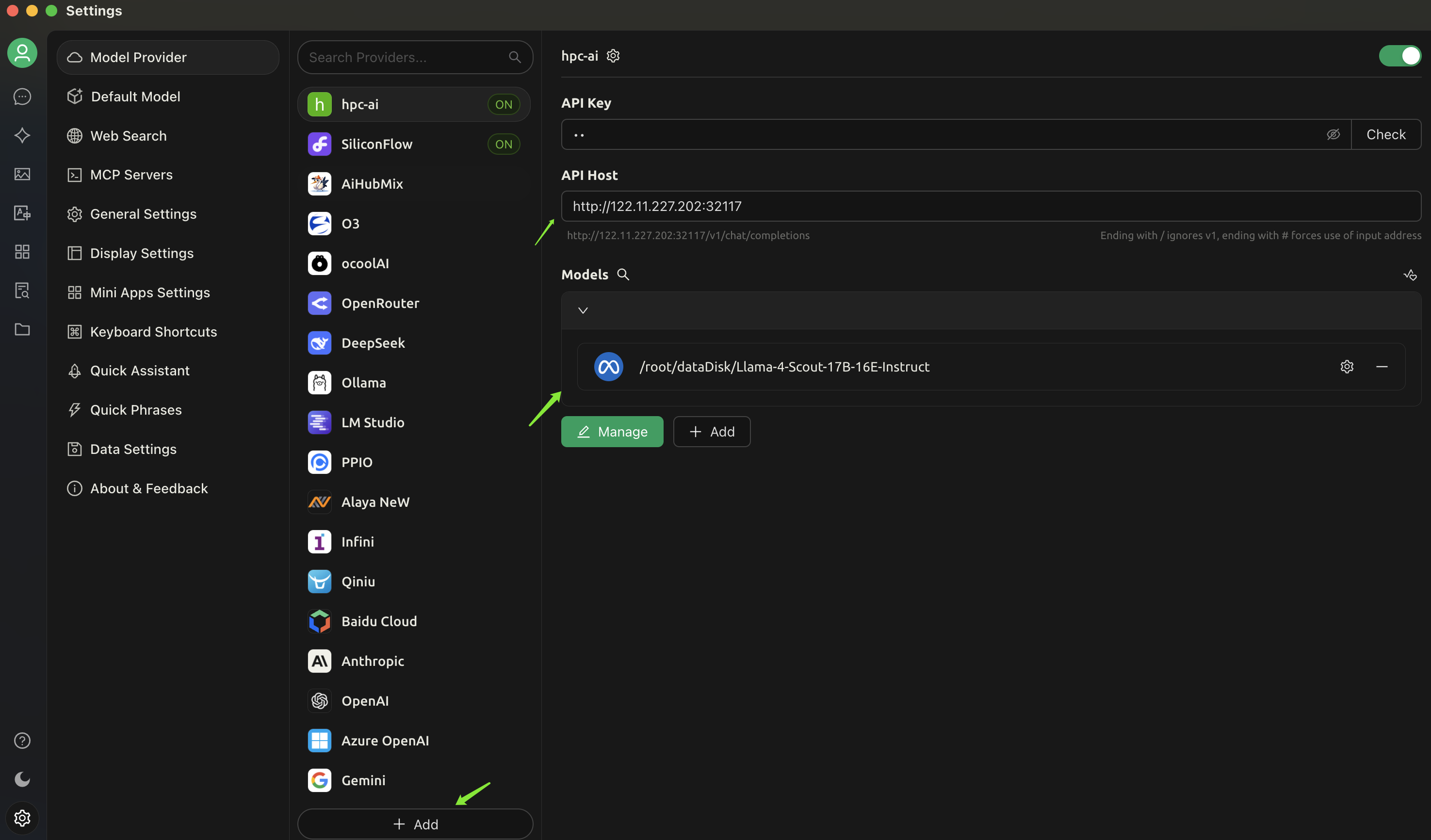
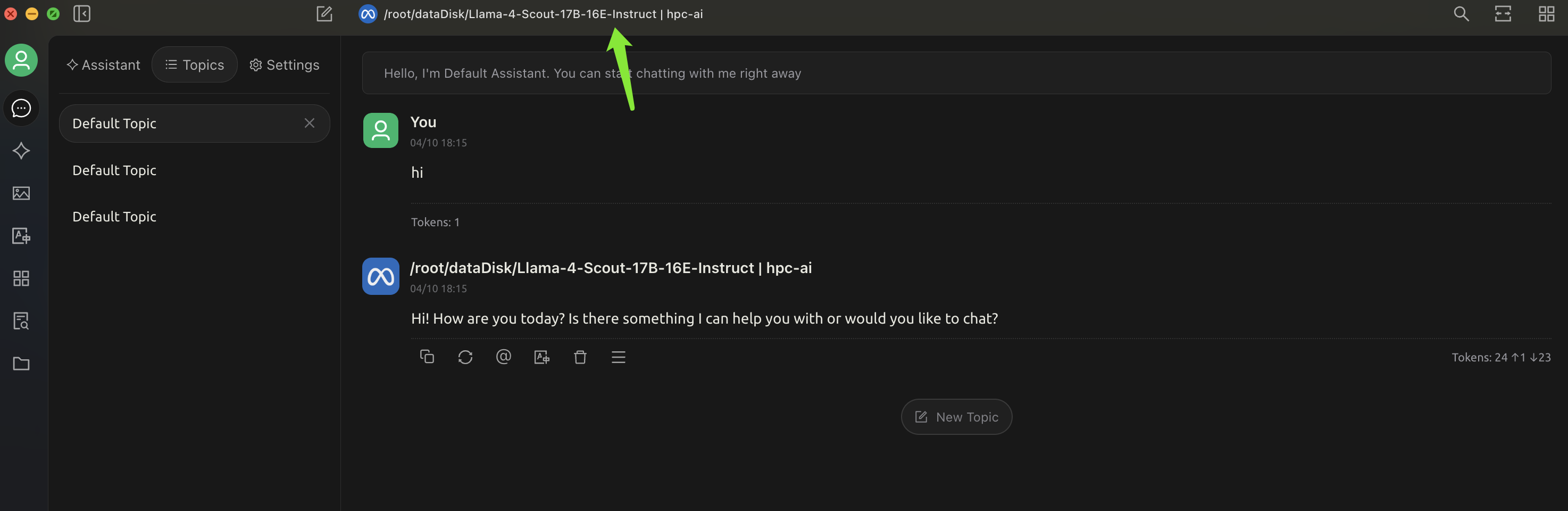
Now you can chat with the inference endpoint in cherry studio.